- Use all learning features, such as tests, quizzes and surveys.
- You can write posts and exchange ideas in our forums.
- We will confirm your participation in some courses.
SMS – Smarte Maschinen Systeme: Daten von smarten Geräten nutzen
Section outline
-
-
Mit dieser Abstimmung möchten wir euer Niveau im Umgang mit Python einschätzen, um Übungen anzupassen und ggf. mehr Unterstützung anzubieten.
-

Relevanz Datengetriebenes Entwickeln -
In dieser Lektion tauchen wir tief in die wesentlichen Aspekte der datengetriebenen Produktentwicklung ein. Wir beginnen mit der Untersuchung, wie Verantwortung in der Produktentwicklung zunehmend auf Einzelpersonen verlagert wird und wie datengetriebene Ansätze helfen können, Unsicherheiten zu reduzieren. Anschließend betrachten wir die komplexen Herausforderungen bei der Entscheidungsfindung in der Produktentwicklung und wie moderne Methoden dazu beitragen können, diese Komplexität zu bewältigen. Schließlich fokussieren wir uns auf die Optimierung des Produkt-Scopes, um schmalere und zielgerichtetere Produkte zu entwickeln. Durch datengetriebene Ansätze lernen wir, wie wir Kosten senken, Komplexität beherrschen und letztendlich effizientere Produkte auf den Markt bringen können.
-
Die zunehmende Komplexität von Produkten und die Verteilung von Verantwortung auf Einzelpersonen führen häufig zu Unsicherheit, die die Produktentwicklung verlangsamen kann. Datengetriebene Methoden helfen dabei, Unsicherheiten zu reduzieren, indem Entscheidungen auf Fakten und Analysen basieren. Diese Ansätze erfordern jedoch neue Technologien und eine offene Arbeitskultur, die datenbasierte Entscheidungsprozesse unterstützt.
-
Die Entwicklung mechanischer Systeme wird zunehmend komplexer, da sich die Anforderungen ständig ändern, Produktzyklen kürzer werden und ein höherer Bedarf an Effizienz und Innovation besteht. Traditionelle Entwicklungsmethoden stoßen hierbei an ihre Grenzen. In diesem Bericht werden die Prinzipien und Vorteile der Produktgenerationsentwicklung (PGE) sowie deren Anwendung zur Bewältigung moderner Herausforderungen mit einem Fokus auf datengetriebene Entscheidungsfindung erläutert.
-
In der modernen Maschinenbauindustrie hat die Komplexität der Produktentwicklung aufgrund von technologischen Fortschritten, steigenden Kundenerwartungen und sich entwickelnden Industriestandards erheblich zugenommen. Die Herausforderungen, die während des Entwicklungsprozesses auftreten, sind vielschichtig und erfordern es, dass Ingenieure mit verschiedenen miteinander verbundenen Faktoren umgehen. Lassen Sie uns diese Herausforderungen im Detail untersuchen:
-
Die Entwicklung schmalerer Produkte ermöglicht es Unternehmen, effizienter auf spezifische Marktanforderungen zu reagieren. Ein klar definierter Scope hilft, den Entwicklungsprozess zu straffen und die Komplexität zu reduzieren. Gleichzeitig muss sichergestellt werden, dass die Produktkomplexität beherrschbar bleibt, um unnötige Kosten und Verzögerungen zu vermeiden. Modularität und klare Strukturen sind Schlüsselstrategien, um die Komplexität von Produkten zu kontrollieren und dabei flexibel genug zu bleiben, um auf individuelle Kundenbedürfnisse einzugehen. Eine solche Strategie schafft die Grundlage für eine wirtschaftlich erfolgreiche Produktentwicklung, die sowohl die Rentabilität als auch die Wettbewerbsfähigkeit stärkt.
-
Die moderne Maschinenbauentwicklung wird zunehmend von einer hohen Komplexität, interdisziplinären Projekten und einem wachsenden Innovationsdruck geprägt. In diesem Kontext hat sich die Rolle der einzelnen Entwickler stark gewandelt. Sie tragen heute mehr Verantwortung für die Entscheidungen, die sie treffen, was einerseits Chancen, aber auch Herausforderungen mit sich bringt. Nachfolgend werden die einzelnen Aspekte dieser Entwicklung detailliert beleuchtet.
-

Begriffe und Grundlagen -
Im Kontext der datengetriebenen Entscheidungsfindung beziehen sich Daten auf faktische, messbare und gesammelte Informationen, die verwendet werden, um Muster zu analysieren, Ergebnisse zu bewerten und Entscheidungen zu treffen. Diese Daten können aus verschiedenen Quellen stammen, wie Kundentransaktionen, Sensordaten, Social-Media-Aktivitäten oder operativen Kennzahlen.
Daten sind das Rückgrat der datengetriebenen Entscheidungsfindung und liefern die faktische Grundlage für die Analyse von Trends, die Bewertung von Ergebnissen und die Entwicklung von Strategien. Sie gewährleisten, dass Entscheidungen objektiv und auf Beweisen statt auf Intuition oder Annahmen basieren. Hochwertige Daten ermöglichen es Organisationen, die Genauigkeit zu verbessern, Chancen zu erkennen, Risiken zu minimieren und die Effizienz zu optimieren. Durch die effektive Nutzung von Daten können Unternehmen fundierte Entscheidungen treffen, die mit ihren Zielen übereinstimmen, sich an verändernde Rahmenbedingungen anpassen und Innovation sowie Wachstum fördern. Kurz gesagt, Daten ermöglichen bessere Entscheidungen, indem sie Rohinformationen in umsetzbare Erkenntnisse verwandeln.
-
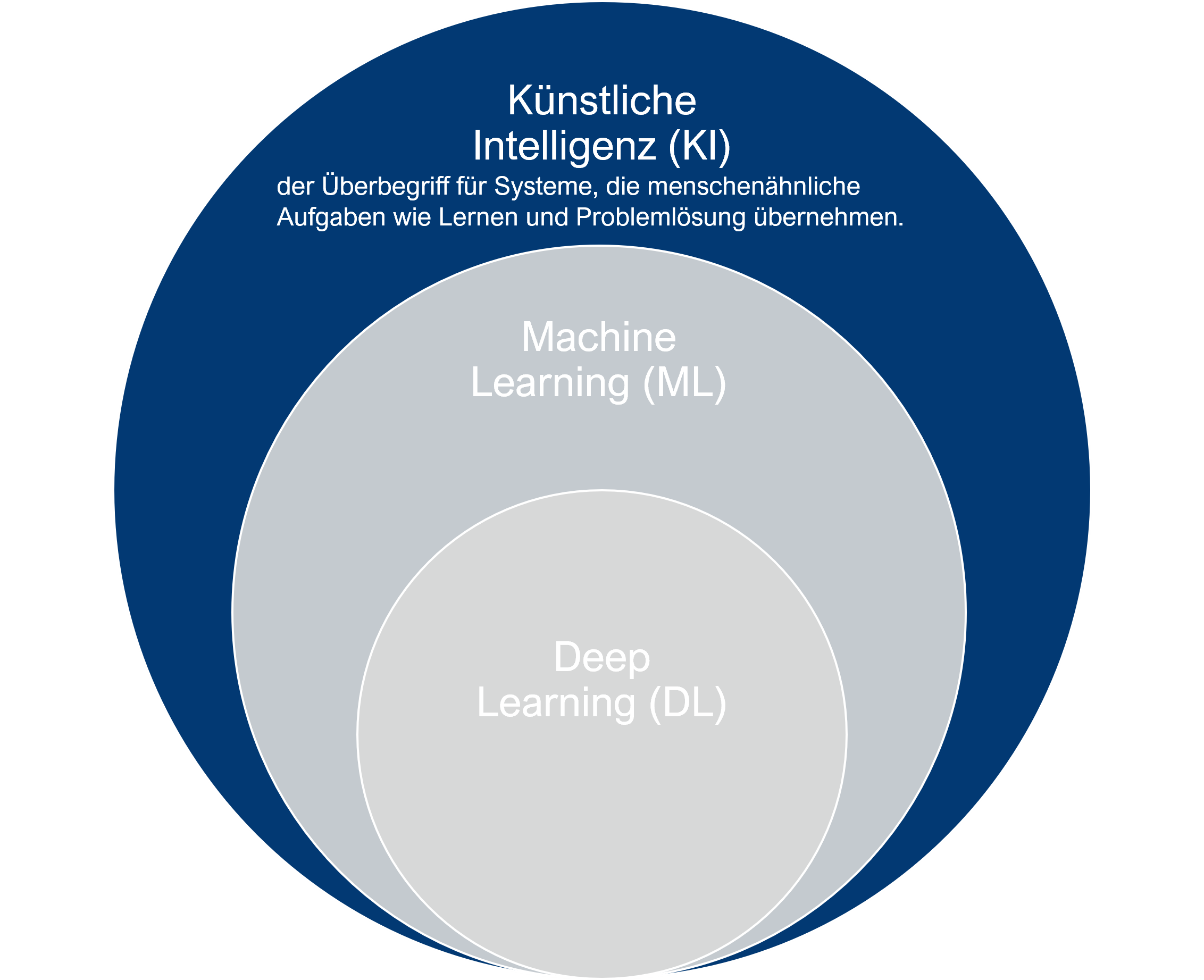
Fokus Künstliche Intelligenz In diesem Abschnitt wirst du die Grundlagen der Künstlichen Intelligenz (KI) kennenlernen, wie sie funktioniert und wie sie unser tägliches Leben beeinflusst. Egal, ob du ein Anfänger bist oder bereits Vorkenntnisse hast, dieser Abschnitt gibt dir einen leicht verständlichen Einstieg in eines der spannendsten Felder der modernen Technologie.
-
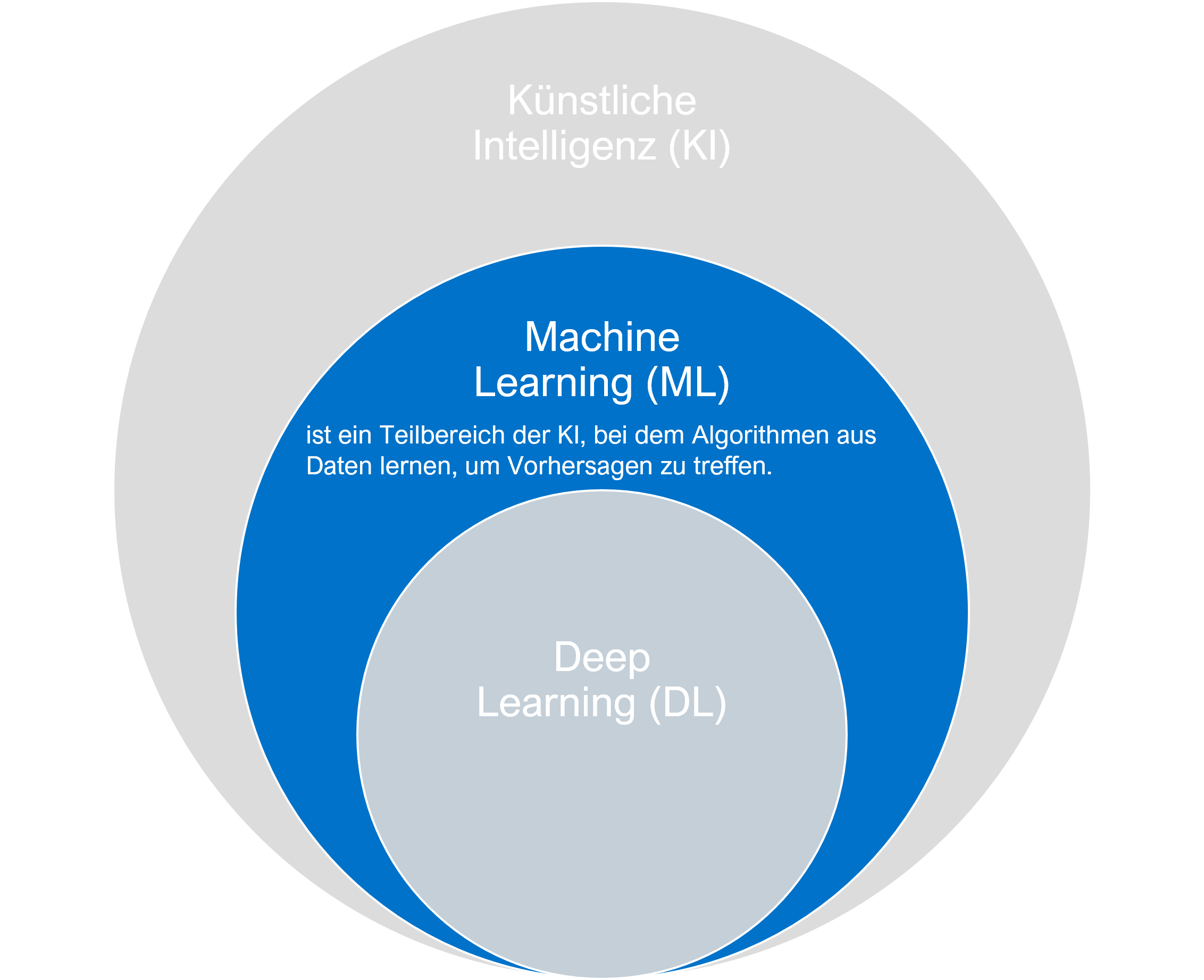
Fokus Machine Learning Maschinelles Lernen (ML) ist ein Teilbereich der Künstlichen Intelligenz, der sich damit beschäftigt, wie Computer durch Erfahrungen lernen können, ohne explizit programmiert werden zu müssen. Die Idee hinter Maschinellem Lernen ist es, Algorithmen zu entwickeln, die aus Daten lernen und basierend auf diesem Wissen Vorhersagen oder Entscheidungen treffen können. Während traditionelle Computerprogramme durch festgelegte Regeln und Anweisungen funktionieren, verwenden ML-Modelle Muster und Zusammenhänge in den Daten, um zu lernen und sich zu verbessern.
Es gibt verschiedene Arten des Maschinellen Lernens, die je nach Art der Daten und der Aufgabenstellung angewendet werden. Grundsätzlich unterscheidet man zwischen überwachten, unüberwachten und bestärkenden Lernmethoden. Überwachtes Lernen verwendet gekennzeichnete Daten, um Modelle zu trainieren, die dann neue, ähnliche Daten klassifizieren oder Vorhersagen treffen können. Unüberwachtes Lernen hingegen arbeitet mit unmarkierten Daten, um Muster oder Strukturen zu erkennen. Das bestärkende Lernen basiert auf dem Prinzip der Belohnung und Bestrafung und wird verwendet, um Agenten zu trainieren, die in einer Umgebung Entscheidungen treffen müssen, um ihre Ziele zu erreichen.
-
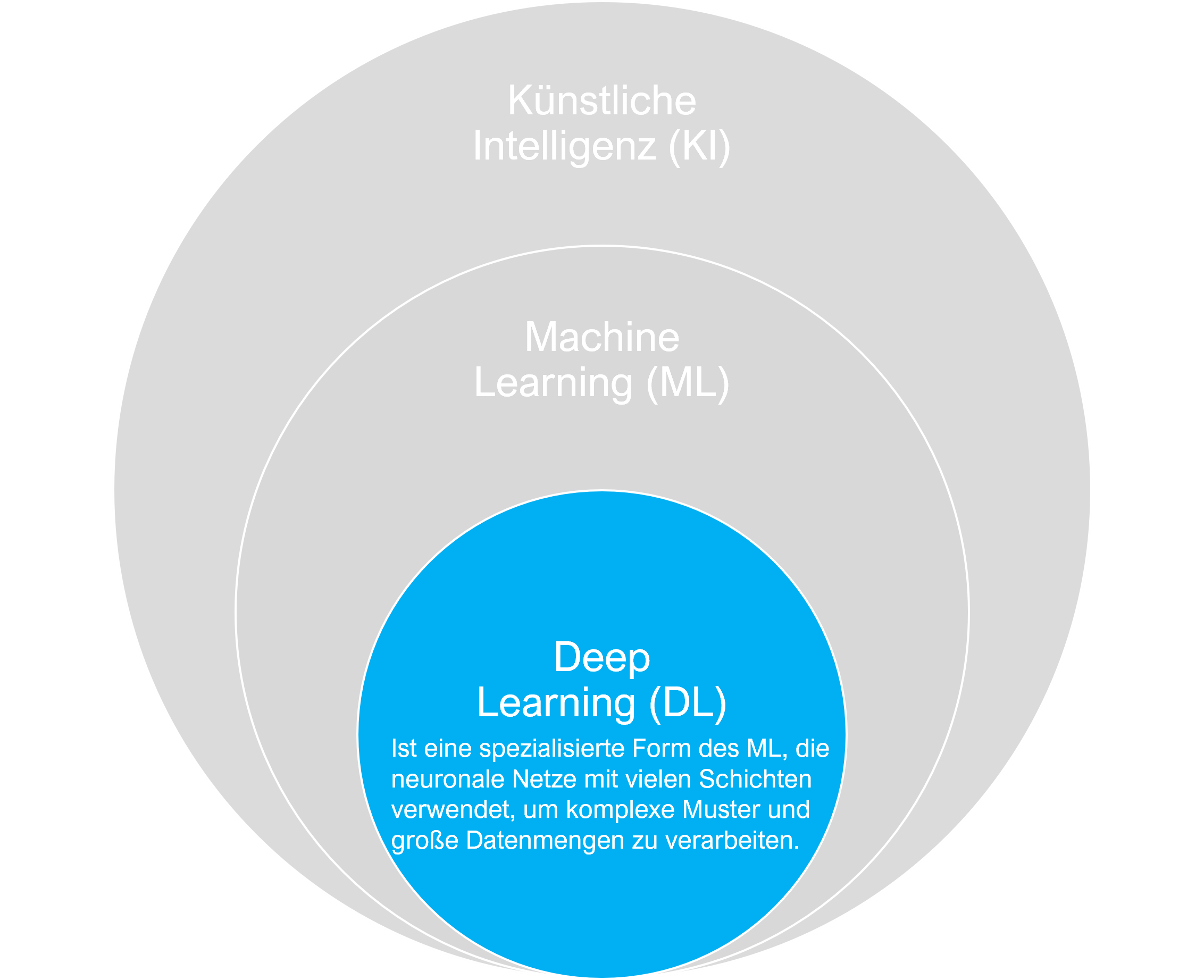
Fokus Deep Learning Deep Learning ist ein spezialisiertes Teilgebiet des Maschinellen Lernens, das auf der Verwendung von künstlichen neuronalen Netzen basiert, die aus vielen Schichten bestehen – daher der Begriff „tief“. Diese tiefen Netzwerke sind in der Lage, komplexe Muster und Beziehungen in großen Datenmengen zu erkennen. Im Gegensatz zu herkömmlichen maschinellen Lernmethoden, die oft manuelle Feature-Extraktion erfordern, kann Deep Learning direkt aus den Rohdaten lernen, indem es eine hierarchische Struktur von Merkmalen aufbaut. Dies ermöglicht es Deep-Learning-Modellen, sehr präzise Ergebnisse in Aufgaben wie Bild- und Spracherkennung zu erzielen.
-

Illustration zum Thema Data Science In unserer zunehmend digitalisierten Welt spielen Daten eine zentrale Rolle. Sie sind der Treibstoff, der moderne Technologien und Innovationen antreibt. Doch um den wahren Wert aus diesen riesigen Datenmengen zu schöpfen, benötigen wir spezialisierte Methoden und Werkzeuge. Begriffe wie Big Data, Data Analytics, Data Mining und Data Science beschreiben verschiedene Ansätze, um Daten zu sammeln, zu analysieren und daraus wertvolle Erkenntnisse zu gewinnen. In diesem Kurs werden wir diese Schlüsselkonzepte erkunden, ihre Unterschiede verstehen und herausfinden, wie sie in der Praxis angewendet werden können. Ob es darum geht, Geschäftsentscheidungen zu treffen, Betrug aufzudecken oder personalisierte Empfehlungen zu erstellen – das Wissen um Datenwissenschaften ist heute unerlässlich.
-
In der heutigen Geschäftswelt haben datengetriebene Entscheidungen einen immer höheren Stellenwert eingenommen. Unternehmen stehen vor der Herausforderung, riesige Mengen an Daten zu sammeln, zu verarbeiten und zu analysieren, um daraus wertvolle Einsichten zu gewinnen. In diesem Kontext spielen verschiedene datengetriebene Methoden eine zentrale Rolle. Von den frühen Anfängen der Datenanalyse bis hin zu modernsten Ansätzen wie KDD, CRISP-DM und der Wagenmann-Methode haben sich bewährte Vorgehensweisen entwickelt, die den Prozess der Datennutzung systematisieren und optimieren.
-
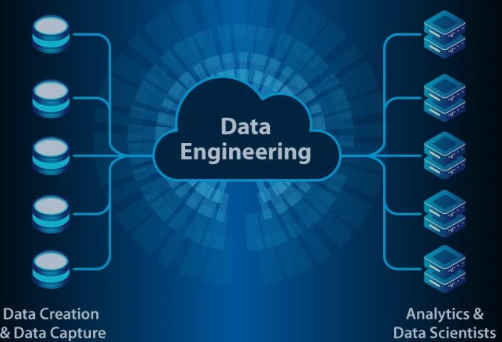
Zusammenfassung von Data Engineering Was ist Data Engineering?
Data Engineering umfasst das Entwerfen, Erstellen und Verwalten von Systemen und Workflows, die die Sammlung, Speicherung, Verarbeitung und Analyse von Daten ermöglichen. Ziel ist es, sicherzustellen, dass Daten zugänglich, von hoher Qualität und effizient für Analysen und Entscheidungsfindung nutzbar sind.
-
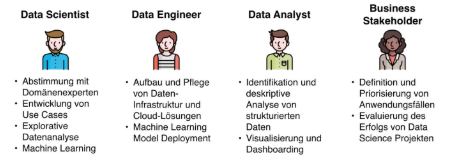
Hauptrollen in einem datengetriebenen Ökosystem In datengetriebenen Ökosystemen sind die vier Hauptrollen – Datenengineering, Datenwissenschaft, Maschinelles Lernen und Domänenexpertise – eng miteinander verbunden und arbeiten in einem kollaborativen Prozess zusammen, um operative und strategische Ziele zu erreichen. Jede Rolle bringt spezifisches Fachwissen ein und kooperiert in verschiedenen Projektphasen, um sicherzustellen, dass das Endergebnis sowohl technisch solide als auch praktisch relevant ist.
Rolle Primäre Aufgabe Hauptbeiträge Datenengineering / Data Engineer Aufbau der Dateninfrastruktur und Datenpipelines für Sammlung, Speicherung und Zugriff. Bereitstellung sauberer, strukturierter und qualitativ hochwertiger Daten für Analyse und Modellierung. Datenwissenschaft / Data Scientist Analyse von Daten zur Identifizierung von Trends, Mustern und umsetzbaren Erkenntnissen. Transformation von Rohdaten in aussagekräftige Informationen; Brücke zwischen Technik und fachlichen Anforderungen. Maschinelles Lernen / Data Analyst Entwicklung von Algorithmen für Vorhersagen, Optimierungen und Automatisierungen. Automatisierung von Entscheidungsprozessen und Entwicklung skalierbarer Lösungen basierend auf analysierten Daten. Domänenexpertise / Business Stakeholder Bereitstellung von tiefgehendem Wissen über den Anwendungskontext, um Relevanz und Machbarkeit sicherzustellen. Präzise Problemdefinition, Validierung von Modellen und Sicherstellung der praktischen und strategischen Ausrichtung. -
Fühlen Sie sich sicher in Ihrem Verständnis der zentralen Konzepte und Zusammenhänge zwischen datenbezogenen Prozessen (z. B. Qualität, Governance, Demokratisierung) und Kompetenzbereichen (z. B. Data Science, Engineering), die in diesem Modul behandelt wurden?
-
-

Vorgehen in der Praxis <Video Wagenmethode>
-
Fortschritte bei Maschinensystemen und datengenerierenden Technologien haben eine neue Ära der Produktentwicklung eingeläutet, insbesondere bei der Analyse von Produkt- und Systemleistungen in realen Einsatzumgebungen. Durch die Integration von Sensoren, IoT-Geräten und fortschrittlicher Analytik erhalten Entwickler beispiellosen Zugang zu Betriebsdaten, die dazu beitragen, Designs zu verbessern, die Zuverlässigkeit zu erhöhen und Kundenbedürfnisse besser zu antizipieren.
-
Datenanalyse nach der Wagenmann Methode 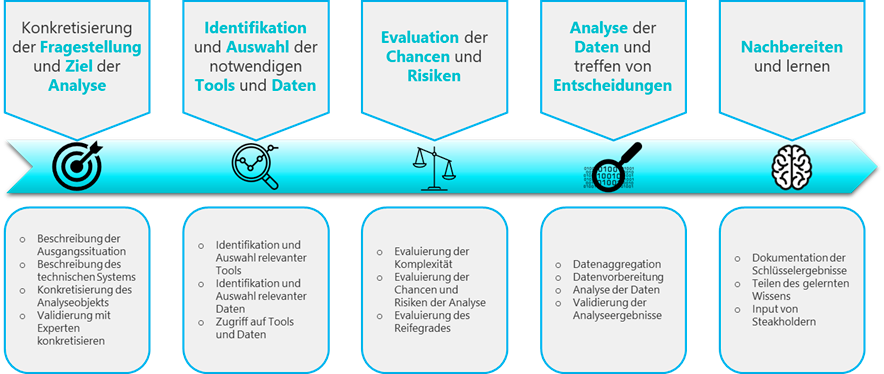
Ansatz einer datengetrieben Entscheidungsfindung Wie der Prozess die Optimierung vorantreibt
Dieser Prozess gewährleistet einen systematischen, datengetriebenen Ansatz für die Entscheidungsfindung. Durch das Befolgen dieser Schritte können Organisationen:
- Probleme präziser angehen, indem klare Ziele definiert werden.
- Relevante Tools und qualitativ hochwertige Daten für eine fundierte Analyse nutzen.
- Risiken minimieren und Chancen maximieren.
- Entscheidungen auf Basis von faktenbasierten Erkenntnissen treffen.
- Eine Kultur des Lernens und der kontinuierlichen Verbesserung fördern.
Dieser Prozess ist besonders relevant in Bereichen wie Fertigung, Geschäftsprozessoptimierung, Kundenmanagement und Produktentwicklung.
-

Anwendung in der Praxis In diesem Abschnitt werden wir uns intensiv mit der Programmiersprache Python beschäftigen, da sie eine der beliebtesten und vielseitigsten Sprachen in der Welt der Datenanalyse und smarten Technologien ist. Python ist bekannt für seine einfache Syntax, umfangreiche Bibliotheken und die Möglichkeit, schnell praxisnahe Lösungen zu entwickeln.
Unser Ziel ist es, die Grundlagen von Python nicht nur theoretisch zu erlernen, sondern direkt anhand praktischer Beispiele anzuwenden. Dabei werden wir die Sprache als Werkzeug nutzen, um Daten zu analysieren, Muster zu erkennen und smarte Systeme zu verstehen. Durch diese praxisorientierte Herangehensweise werden Sie Python effektiv in Ihren Projekten einsetzen können.
-
-
In diesem Kapitel werden wir drei wesentliche Datentypen in Python kennenlernen: Listen, Tupel und Wörterbücher. Listen sind flexible, geordnete Sammlungen von Elementen, die verändert werden können, was sie ideal zum Speichern von Datensequenzen macht, bei denen es notwendig sein kann, Elemente hinzuzufügen, zu entfernen oder zu ändern. Tupel hingegen sind ähnlich wie Listen, aber unveränderlich, was bedeutet, dass ihr Inhalt nach der Erstellung nicht mehr geändert werden kann. Sie sind daher ideal, um feste Daten zu speichern, die nicht verändert werden sollten. Wörterbücher sind ungeordnete Sammlungen von Schlüssel-Wert-Paaren, die eine effiziente Datenabfrage durch die Verwendung von einzigartigen Schlüsseln ermöglichen, und sind perfekt geeignet, um strukturierte Daten darzustellen, wie etwa das Speichern von Attributen eines Objekts oder das Zuordnen von Werten. Zusammen bilden diese Datentypen grundlegende Werkzeuge zum Organisieren und Verwalten von Daten in Python.
-
Schleifen in Python werden verwendet, um wiederkehrende Aufgaben zu automatisieren, sodass ein Codeblock mehrfach ausgeführt werden kann, ohne ihn manuell zu wiederholen. Dies macht Programme effizienter und kürzer, besonders bei der Arbeit mit großen Datensätzen oder wenn dieselbe Operation über viele Elemente hinweg durchgeführt werden muss. Schleifen helfen dabei, Aufgaben wie das Durchlaufen von Listen, das Verarbeiten von Elementen oder das kontinuierliche Ausführen von Code bis eine bestimmte Bedingung erfüllt ist, zu vereinfachen. Durch die Verwendung von Schleifen können Sie den Code redundanzfrei halten, die Lesbarkeit verbessern und Ihre Programme dynamischer und skalierbarer machen.
In diesem Kapitel werden wir zwei grundlegende Schleifenstrukturen in Python kennenlernen: die For-Schleife und die While-Schleife. Die For-Schleife wird verwendet, um über eine Sequenz (wie eine Liste, ein Tupel oder einen String) zu iterieren, sodass ein Codeblock für jedes Element in der Sequenz mehrfach ausgeführt wird. Sie ist ideal, wenn Sie im Voraus wissen, wie oft eine Aufgabe wiederholt werden muss. Die While-Schleife hingegen führt einen Codeblock so lange aus, wie eine bestimmte Bedingung wahr bleibt. Sie eignet sich perfekt für Situationen, in denen die Anzahl der Wiederholungen im Voraus nicht bekannt ist und Sie so lange wiederholen möchten, bis eine bestimmte Bedingung erfüllt ist. Zusammen bieten diese Schleifen mächtige Möglichkeiten, wiederkehrende Aufgaben zu automatisieren und dynamische Szenarien in Ihren Python-Programmen zu behandeln.
-
Eine for-Schleife in Python wird verwendet, um über eine Sequenz wie eine Liste, ein Tupel oder einen String zu iterieren und einen Codeblock für jedes Element in dieser Sequenz auszuführen. Sie ist besonders nützlich, wenn die Anzahl der Iterationen im Voraus bekannt ist oder wenn eine Aufgabe für jedes Element in einer Sammlung ausgeführt werden muss. Die Syntax ist einfach: Sie definieren die Sequenz und geben den Codeblock an, der für jedes Element wiederholt werden soll. Sie hilft, wiederkehrende Aufgaben zu automatisieren und macht den Code sauberer und effizienter.
-
Wir nutzen Google Colab als paralleles Tool bzw. Werkzeug um die folgenden Übungen umzusetzen und das Programmieren mit Python anhand von Beispielen iterativ zu erlernen.
Viel Erfolg!
-
Smarte Produkte im Alltag und die Relevanz der Daten -
Die explorative Datenanalyse (Exploratory Data Analysis, EDA) ist ein wesentlicher Schritt, um die Struktur, die Muster und mögliche Zusammenhänge in einem Datensatz zu verstehen.
1. Überblick über den Datensatz verschaffen
Datensatz laden:
-
- Importieren Sie den Datensatz in Python, z. B. mit Pandas:
-
import pandas as pddf = pd.read_csv("daten.csv")
Erste Zeilen anzeigen:
- Nutzen Sie
df.head(), um sich die ersten Zeilen des Datensatzes anzusehen und ein Gefühl für die Struktur und den Inhalt zu bekommen. - Verwenden Sie
df.info(), um Informationen über die Anzahl der Zeilen, Spalten und die Datentypen zu erhalten - Verwenden Sie
df.shapeum die Anzahl der Zeilen und Spalten zu sehen
2. Statistische Zusammenfassung erstellen
Daten analysieren:
- Nutzen Sie df.describe(), um zentrale statistische Maße wie Mittelwert, Median, Minimum und Maximum für numerische Spalten zu berechnen
- Kategorische Daten untersuchen: Nutzen Sie
df['Spaltenname'].value_counts(), um die Häufigkeit der Werte in einer Spalte zu analysieren
3. Fehlende Werte identifizieren
- Nutzen Sie
df.isnull().sum(), um zu sehen, wie viele fehlende Werte in jeder Spalte vorhanden sind
4. Datenverteilung visualisieren
Histogramme erstellen:
- Nutzen Sie
df['Spaltenname'].hist(), um die Verteilung einer numerischen Spalte zu visualisieren - Nutzen Sie Boxplots, um Ausreißer und die Verteilung zu untersuchen
import matplotlib.pyplot as pltdf.boxplot(column='Spaltenname')plt.show()- Prüfen Sie Korrelationen zwischen numerischen Spalten mit
df.corr()
5. Einblicke und Auffälligkeiten notieren
Stellen Sie sich folgende Fragen:- Gibt es unerwartete oder ungewöhnliche Werte?
- Gibt es Ausreißer, die möglicherweise korrigiert oder ignoriert werden sollten?
- Welche Muster und Trends erkennen Sie in den Daten?
- Dokumentieren Sie Ihre Beobachtungen in einem Notizbuch oder einer Datei, um später darauf zurückgreifen zu können
6. Daten für weitere Analysen vorbereiten
Daten bereinigen:- Entfernen oder füllen Sie fehlende Werte, wenn notwendig mit
df['Spaltenname'].fillna(df['Spaltenname'].mean(), inplace=True)
Nächste Schritte
Nachdem Sie die Daten durch die explorative Analyse besser verstanden haben, können Sie spezifische Fragestellungen oder Hypothesen testen und Ihre Erkenntnisse visualisieren. Denken Sie daran: Eine gute EDA ist die Basis für jede erfolgreiche Datenanalyse! -
-
Opened: Monday, 9 December 2024, 12:00 AMDue: Monday, 16 December 2024, 12:00 AM
Aufgabe: Erstellen Sie Altersgruppen und untersuchen Sie, welche Gruppe die Smartwatches am intensivsten nutzt und welche am aktivsten ist. Berechnen Sie die Durchschnittswerte der Nutzungsdauer und der Schritte für jede Altersgruppe und visualisieren Sie die Ergebnisse.
Vorgehen:
- Erstellen Sie Altersgruppen mit geeigneten Grenzen (z. B. 18–29 Jahre, 30–44 Jahre, 45–62 Jahre).
- Gruppieren Sie die Daten basierend auf den Altersgruppen.
- Berechnen Sie die Durchschnittswerte der Spalten
Nutzungsdauer_MonateundSchritte_pro_Woche. - Visualisieren Sie die Ergebnisse mit einem Balkendiagramm.
import pandas as pd import matplotlib.pyplot as plt# Schritt 1: Altersgruppen definieren
# Definieren Sie die Altersgruppen und verwenden Sie `pd.cut`, um die Spaltenwerte in Gruppen zu unterteilen
# Beispiel: bins = [18, 29, 44, 62] und labels = ['18–29 Jahre', '30–44 Jahre', '45–62 Jahre'] # Altersgruppen erstellen
# df['Altersgruppe'] = pd.cut(...)
# Schritt 2: Daten gruppieren
# Gruppieren Sie die Daten nach der neuen Spalte 'Altersgruppe' und berechnen Sie die Durchschnittswerte
# gruppen_statistik = df.groupby(...)[...].mean()
# Schritt 3: Ergebnisse visualisieren
# gruppen_statistik.plot(...)
# plt.title(...)
# plt.show()
-
Opened: Monday, 9 December 2024, 12:00 AMDue: Monday, 16 December 2024, 12:00 AM
Aufgabe: Untersuchen Sie, ob Nutzer mit höherem Aktivitätslevel eine bessere Schlafqualität haben. Gruppieren Sie die Daten nach
Aktivitätslevelund berechnen Sie den Durchschnitt der SpalteSchlafqualität_Score. Stellen Sie die Ergebnisse in einem Diagramm dar.Vorgehen:
- Gruppieren Sie die Daten nach
Aktivitätslevel. - Berechnen Sie den durchschnittlichen Schlafqualitäts-Score für jedes Aktivitätslevel.
- Stellen Sie die Ergebnisse in einem Balkendiagramm dar.
# Schritt 1: Daten gruppieren
# Gruppieren Sie die Daten nach 'Aktivitätslevel' und berechnen Sie den Mittelwert der Spalte 'Schlafqualität_Score'
# schlaf_aktivitätslevel = df.groupby(...)[...].mean()# Schritt 2: Ergebnisse visualisieren
# schlaf_aktivitätslevel.plot(kind='bar', ...)
# plt.title(...)
# plt.show() - Gruppieren Sie die Daten nach
-
Opened: Monday, 9 December 2024, 12:00 AMDue: Monday, 16 December 2024, 12:00 AM
Aufgabe: Vergleichen Sie die Nutzungsmuster (z. B. Nutzungsdauer, Bildschirmzeit, Schritte) der verschiedenen Smartwatch-Modelle. Berechnen Sie Durchschnittswerte für jede dieser Spalten und visualisieren Sie die Ergebnisse.
Vorgehen:
- Gruppieren Sie die Daten nach
Smartwatch. - Berechnen Sie die Durchschnittswerte für die Spalten
Nutzungsdauer_Monate,Bildschirmzeit_StundenundSchritte_pro_Woche. - Stellen Sie die Ergebnisse in einem Balkendiagramm dar.
# Schritt 1: Daten gruppieren
# Gruppieren Sie die Daten nach 'Smartwatch' und berechnen Sie die Mittelwerte der gewünschten Spalten
# nutzung_smartwatch = df.groupby(...)[[...]].mean()# Schritt 2: Ergebnisse visualisieren
# nutzung_smartwatch.plot(kind='bar', ...)
# plt.title(...)
# plt.show() - Gruppieren Sie die Daten nach
-

-

Designed by Freepik
Wir planen zukünftig einen spannenden 2-tägigen Hackathon, bei dem reale Fragestellungen aus der Produktentwicklung in der Industrie im Fokus stehen. In interdisziplinären Teams werden Daten analysiert, innovative Konzepte entwickelt und kreative Lösungen erarbeitet, um Produkte zukunftsfähig weiterzuentwickeln.
Dieser Hackathon bietet die perfekte Gelegenheit, praktische Erfahrungen zu sammeln, im Team zu wachsen und echte Herausforderungen zu meistern. Seid dabei und gestaltet die Produkte von morgen!
Weitere Details folgen – bleibt gespannt!
-




