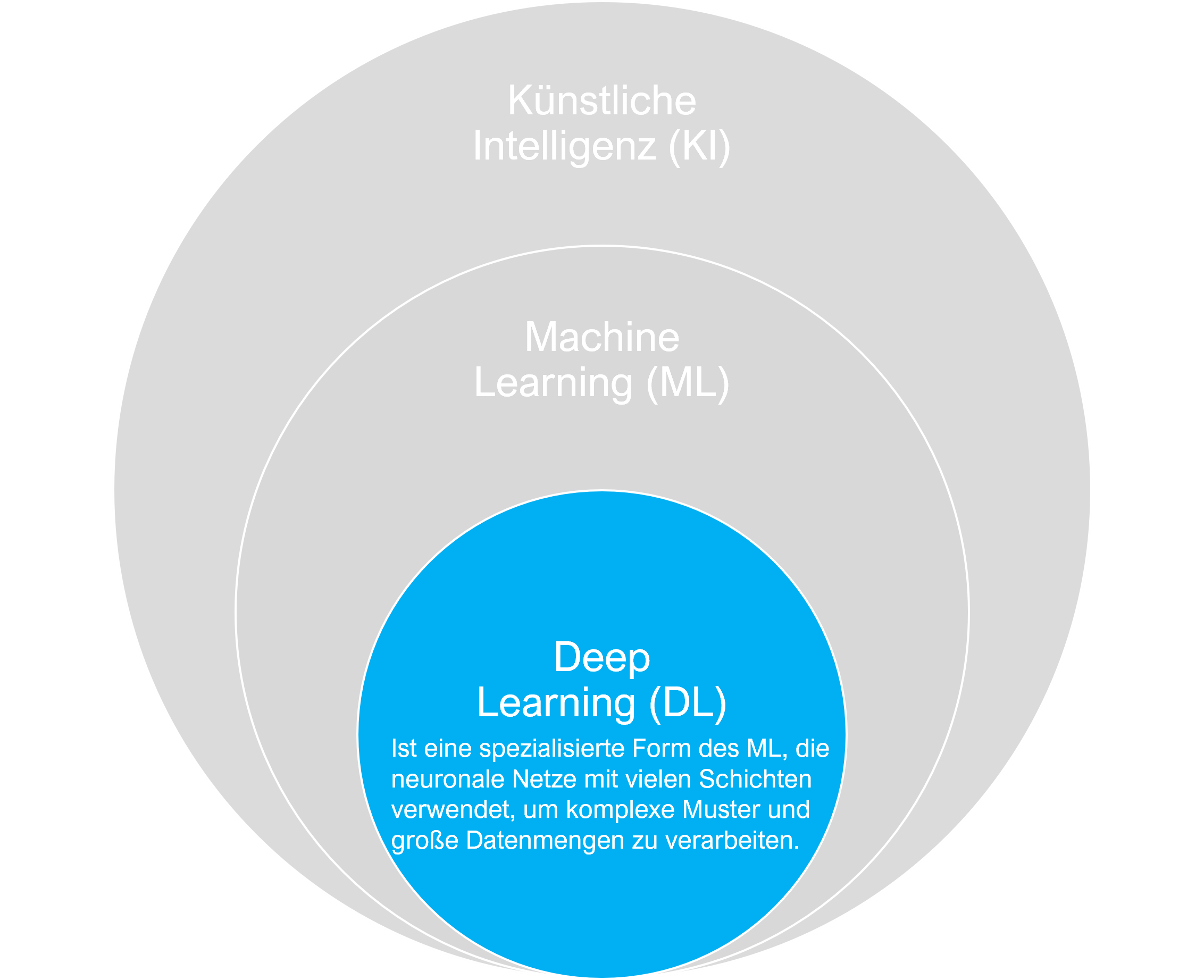
Deep Learning ist ein spezialisiertes Teilgebiet des Maschinellen Lernens, das auf der Verwendung von künstlichen neuronalen Netzen basiert, die aus vielen Schichten bestehen – daher der Begriff „tief“. Diese tiefen Netzwerke sind in der Lage, komplexe Muster und Beziehungen in großen Datenmengen zu erkennen. Im Gegensatz zu herkömmlichen maschinellen Lernmethoden, die oft manuelle Feature-Extraktion erfordern, kann Deep Learning direkt aus den Rohdaten lernen, indem es eine hierarchische Struktur von Merkmalen aufbaut. Dies ermöglicht es Deep-Learning-Modellen, sehr präzise Ergebnisse in Aufgaben wie Bild- und Spracherkennung zu erzielen.
Du hast einige Seiten der Lektion schon einmal bearbeitet. Möchtest du an der Stelle weitermachen, an der du damals aufgehört hast?