Grundlagen und Begriffe
Section outline
-

Begriffe und Grundlagen -
Im Kontext der datengetriebenen Entscheidungsfindung beziehen sich Daten auf faktische, messbare und gesammelte Informationen, die verwendet werden, um Muster zu analysieren, Ergebnisse zu bewerten und Entscheidungen zu treffen. Diese Daten können aus verschiedenen Quellen stammen, wie Kundentransaktionen, Sensordaten, Social-Media-Aktivitäten oder operativen Kennzahlen.
Daten sind das Rückgrat der datengetriebenen Entscheidungsfindung und liefern die faktische Grundlage für die Analyse von Trends, die Bewertung von Ergebnissen und die Entwicklung von Strategien. Sie gewährleisten, dass Entscheidungen objektiv und auf Beweisen statt auf Intuition oder Annahmen basieren. Hochwertige Daten ermöglichen es Organisationen, die Genauigkeit zu verbessern, Chancen zu erkennen, Risiken zu minimieren und die Effizienz zu optimieren. Durch die effektive Nutzung von Daten können Unternehmen fundierte Entscheidungen treffen, die mit ihren Zielen übereinstimmen, sich an verändernde Rahmenbedingungen anpassen und Innovation sowie Wachstum fördern. Kurz gesagt, Daten ermöglichen bessere Entscheidungen, indem sie Rohinformationen in umsetzbare Erkenntnisse verwandeln.
-
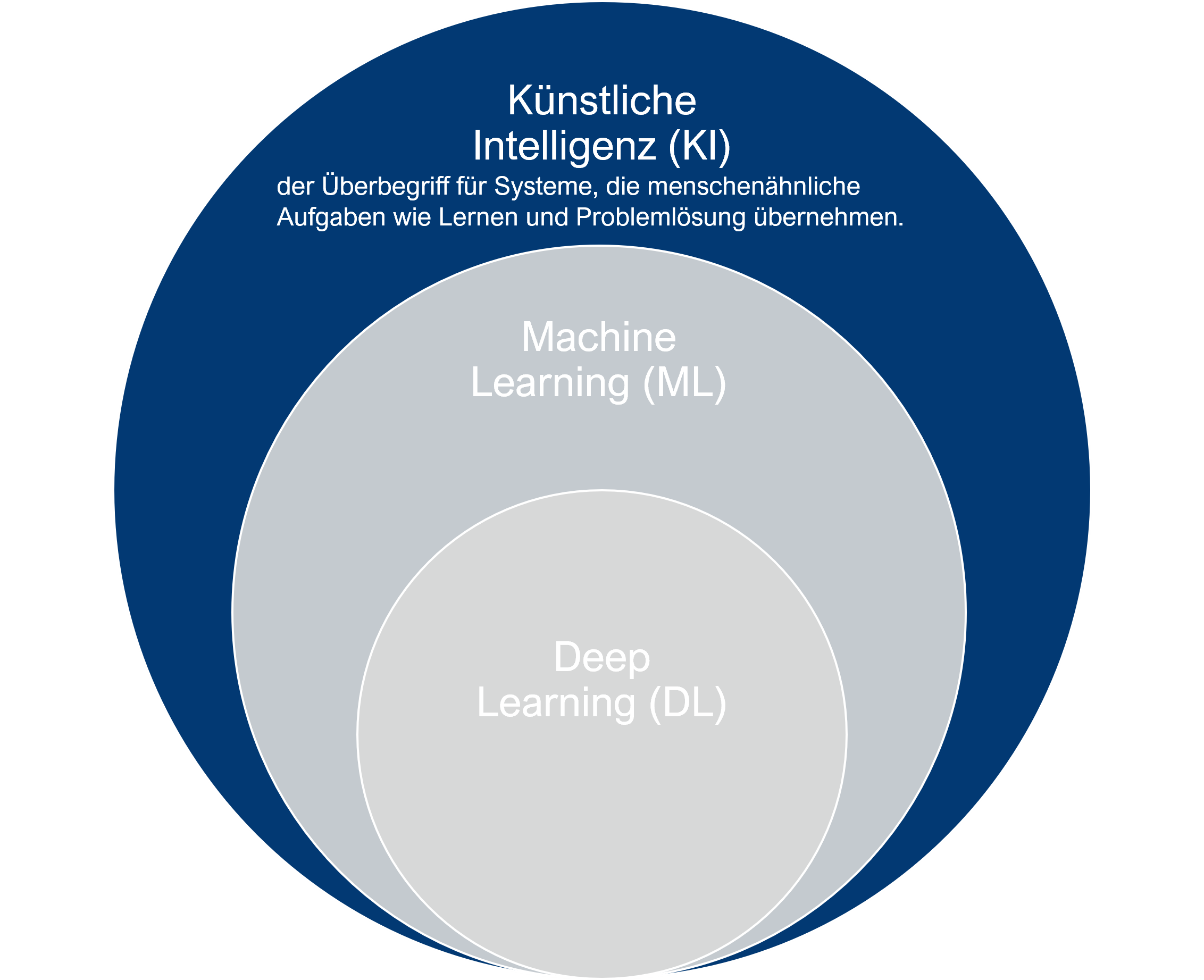
Fokus Künstliche Intelligenz In diesem Abschnitt wirst du die Grundlagen der Künstlichen Intelligenz (KI) kennenlernen, wie sie funktioniert und wie sie unser tägliches Leben beeinflusst. Egal, ob du ein Anfänger bist oder bereits Vorkenntnisse hast, dieser Abschnitt gibt dir einen leicht verständlichen Einstieg in eines der spannendsten Felder der modernen Technologie.
-
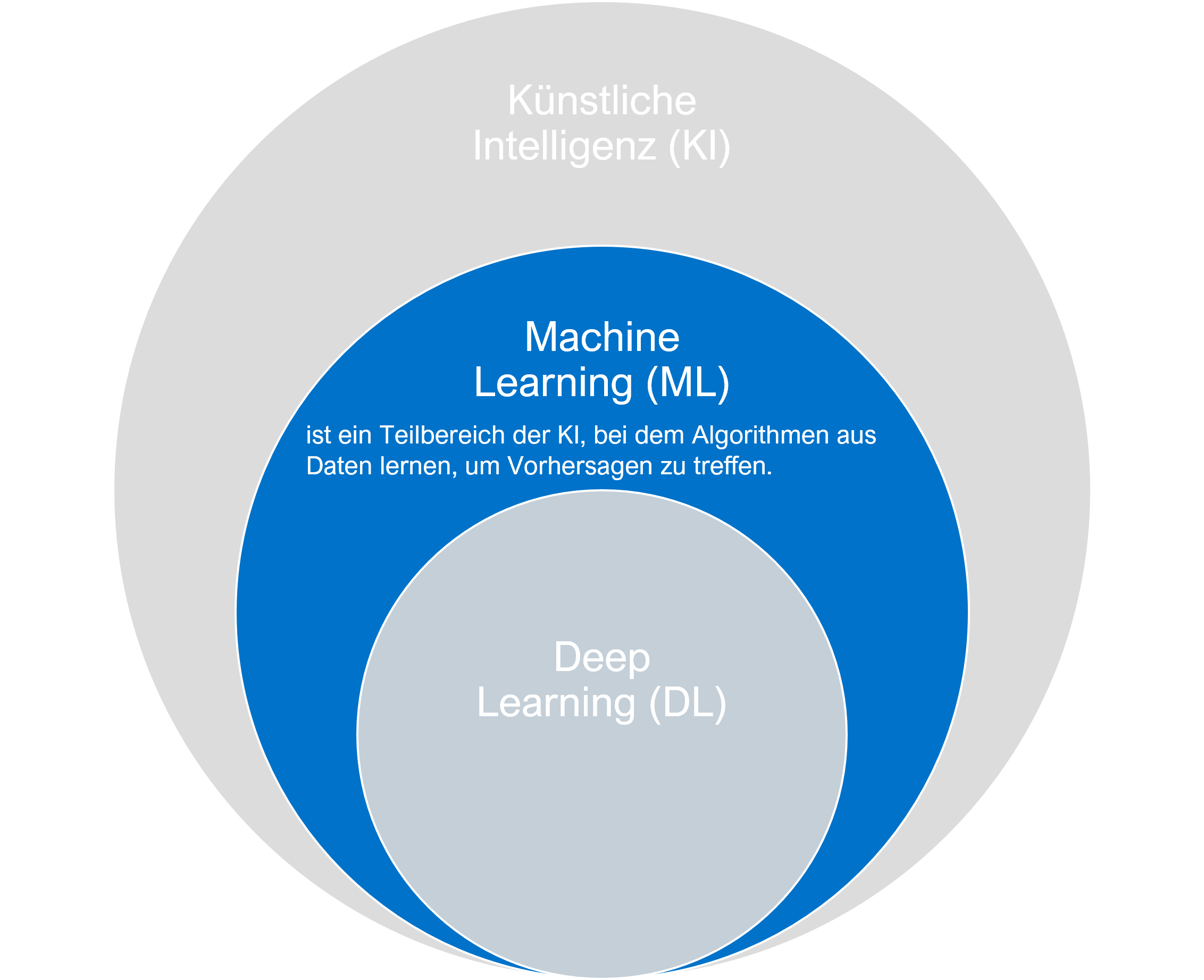
Fokus Machine Learning Maschinelles Lernen (ML) ist ein Teilbereich der Künstlichen Intelligenz, der sich damit beschäftigt, wie Computer durch Erfahrungen lernen können, ohne explizit programmiert werden zu müssen. Die Idee hinter Maschinellem Lernen ist es, Algorithmen zu entwickeln, die aus Daten lernen und basierend auf diesem Wissen Vorhersagen oder Entscheidungen treffen können. Während traditionelle Computerprogramme durch festgelegte Regeln und Anweisungen funktionieren, verwenden ML-Modelle Muster und Zusammenhänge in den Daten, um zu lernen und sich zu verbessern.
Es gibt verschiedene Arten des Maschinellen Lernens, die je nach Art der Daten und der Aufgabenstellung angewendet werden. Grundsätzlich unterscheidet man zwischen überwachten, unüberwachten und bestärkenden Lernmethoden. Überwachtes Lernen verwendet gekennzeichnete Daten, um Modelle zu trainieren, die dann neue, ähnliche Daten klassifizieren oder Vorhersagen treffen können. Unüberwachtes Lernen hingegen arbeitet mit unmarkierten Daten, um Muster oder Strukturen zu erkennen. Das bestärkende Lernen basiert auf dem Prinzip der Belohnung und Bestrafung und wird verwendet, um Agenten zu trainieren, die in einer Umgebung Entscheidungen treffen müssen, um ihre Ziele zu erreichen.
-
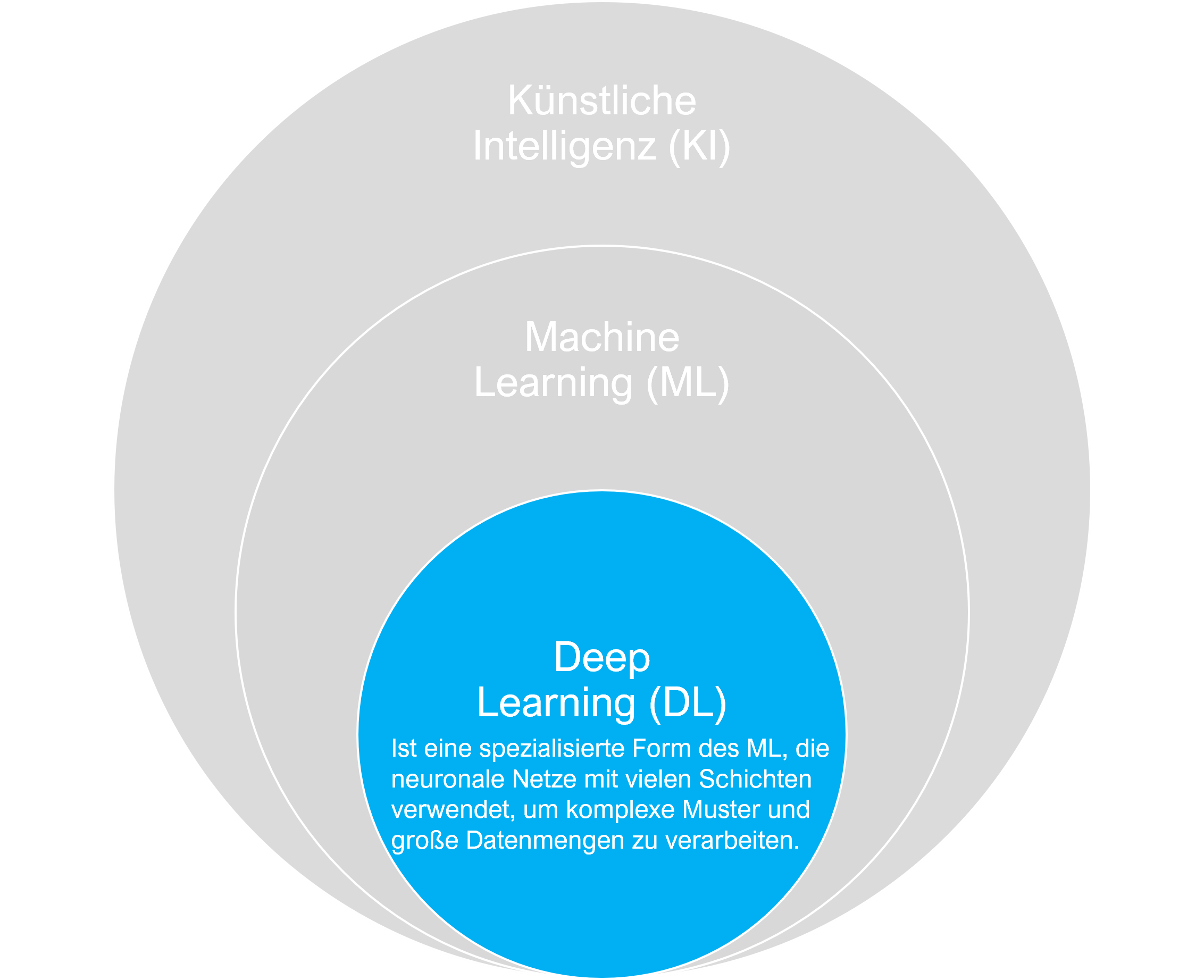
Fokus Deep Learning Deep Learning ist ein spezialisiertes Teilgebiet des Maschinellen Lernens, das auf der Verwendung von künstlichen neuronalen Netzen basiert, die aus vielen Schichten bestehen – daher der Begriff „tief“. Diese tiefen Netzwerke sind in der Lage, komplexe Muster und Beziehungen in großen Datenmengen zu erkennen. Im Gegensatz zu herkömmlichen maschinellen Lernmethoden, die oft manuelle Feature-Extraktion erfordern, kann Deep Learning direkt aus den Rohdaten lernen, indem es eine hierarchische Struktur von Merkmalen aufbaut. Dies ermöglicht es Deep-Learning-Modellen, sehr präzise Ergebnisse in Aufgaben wie Bild- und Spracherkennung zu erzielen.
-

Illustration zum Thema Data Science In unserer zunehmend digitalisierten Welt spielen Daten eine zentrale Rolle. Sie sind der Treibstoff, der moderne Technologien und Innovationen antreibt. Doch um den wahren Wert aus diesen riesigen Datenmengen zu schöpfen, benötigen wir spezialisierte Methoden und Werkzeuge. Begriffe wie Big Data, Data Analytics, Data Mining und Data Science beschreiben verschiedene Ansätze, um Daten zu sammeln, zu analysieren und daraus wertvolle Erkenntnisse zu gewinnen. In diesem Kurs werden wir diese Schlüsselkonzepte erkunden, ihre Unterschiede verstehen und herausfinden, wie sie in der Praxis angewendet werden können. Ob es darum geht, Geschäftsentscheidungen zu treffen, Betrug aufzudecken oder personalisierte Empfehlungen zu erstellen – das Wissen um Datenwissenschaften ist heute unerlässlich.
-
In der heutigen Geschäftswelt haben datengetriebene Entscheidungen einen immer höheren Stellenwert eingenommen. Unternehmen stehen vor der Herausforderung, riesige Mengen an Daten zu sammeln, zu verarbeiten und zu analysieren, um daraus wertvolle Einsichten zu gewinnen. In diesem Kontext spielen verschiedene datengetriebene Methoden eine zentrale Rolle. Von den frühen Anfängen der Datenanalyse bis hin zu modernsten Ansätzen wie KDD, CRISP-DM und der Wagenmann-Methode haben sich bewährte Vorgehensweisen entwickelt, die den Prozess der Datennutzung systematisieren und optimieren.
-
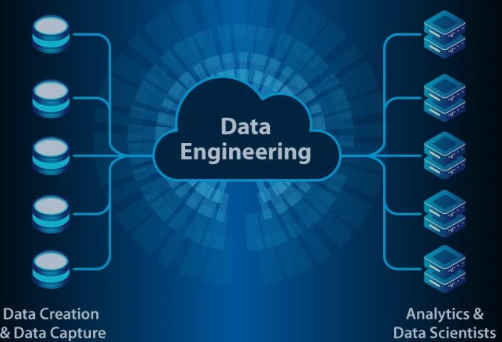
Zusammenfassung von Data Engineering Was ist Data Engineering?
Data Engineering umfasst das Entwerfen, Erstellen und Verwalten von Systemen und Workflows, die die Sammlung, Speicherung, Verarbeitung und Analyse von Daten ermöglichen. Ziel ist es, sicherzustellen, dass Daten zugänglich, von hoher Qualität und effizient für Analysen und Entscheidungsfindung nutzbar sind.
-
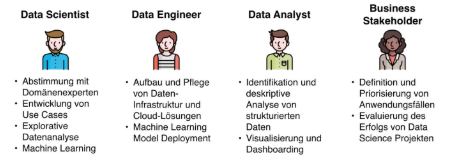
Hauptrollen in einem datengetriebenen Ökosystem In datengetriebenen Ökosystemen sind die vier Hauptrollen – Datenengineering, Datenwissenschaft, Maschinelles Lernen und Domänenexpertise – eng miteinander verbunden und arbeiten in einem kollaborativen Prozess zusammen, um operative und strategische Ziele zu erreichen. Jede Rolle bringt spezifisches Fachwissen ein und kooperiert in verschiedenen Projektphasen, um sicherzustellen, dass das Endergebnis sowohl technisch solide als auch praktisch relevant ist.
Rolle Primäre Aufgabe Hauptbeiträge Datenengineering / Data Engineer Aufbau der Dateninfrastruktur und Datenpipelines für Sammlung, Speicherung und Zugriff. Bereitstellung sauberer, strukturierter und qualitativ hochwertiger Daten für Analyse und Modellierung. Datenwissenschaft / Data Scientist Analyse von Daten zur Identifizierung von Trends, Mustern und umsetzbaren Erkenntnissen. Transformation von Rohdaten in aussagekräftige Informationen; Brücke zwischen Technik und fachlichen Anforderungen. Maschinelles Lernen / Data Analyst Entwicklung von Algorithmen für Vorhersagen, Optimierungen und Automatisierungen. Automatisierung von Entscheidungsprozessen und Entwicklung skalierbarer Lösungen basierend auf analysierten Daten. Domänenexpertise / Business Stakeholder Bereitstellung von tiefgehendem Wissen über den Anwendungskontext, um Relevanz und Machbarkeit sicherzustellen. Präzise Problemdefinition, Validierung von Modellen und Sicherstellung der praktischen und strategischen Ausrichtung. -
Fühlen Sie sich sicher in Ihrem Verständnis der zentralen Konzepte und Zusammenhänge zwischen datenbezogenen Prozessen (z. B. Qualität, Governance, Demokratisierung) und Kompetenzbereichen (z. B. Data Science, Engineering), die in diesem Modul behandelt wurden?
-