1.2 KI-Typen: Schwache vs. starke KI
1.2 KI-Typen: Schwache vs. starke KI
KI wirkt oft magisch, aber hinter den Kulissen arbeiten Wahrscheinlichkeiten und gigantische Datenmengen. Also wie weit kann KI denken?
Leitfrage: Was ist möglich?
Die grundlegendste Unterscheidung bei KI-Systemen betrifft ihren Fähigkeitsumfang:
-
Schwache (oder enge) KI ist auf klar umrissene Aufgaben beschränkt. Sie folgt festen Regeln und reagiert auf definierte Eingaben – etwa bei der Transkription von Vorlesungen, der Plagiatserkennung, Raumplanung oder Modellierung komplexer Systeme. Solche Systeme funktionieren nur in ihrem Spezialgebiet – kreativ oder flexibel sind sie nicht. Alle heute eingesetzten KI-Anwendungen gehören in diese Kategorie.
-
Starke (oder allgemeine) KI könnte dagegen eigenständig Aufgaben erkennen, sich Wissen aneignen, Probleme analysieren und kreative Lösungen entwickeln. Solche Systeme existieren bisher nicht, auch wenn fortgeschrittene Chat-Assistenten diesem Ideal näherkommen.
Oft wird zusätzlich zwischen Artificial General Intelligence (AGI) – also menschenähnlicher Intelligenz – und einer hypothetischen Artificial Superintelligence (ASI) unterschieden, die menschliche Fähigkeiten weit übertrifft. Diese Konzepte sind theoretisch und insbesondere die "Superintelligenz" problematisch, denn: Auch enge KIs übertreffen den Menschen bereits in bestimmten Einzelleistungen (z. B. Rechenleistung).
📌 Praxisrelevanz: Diese Unterscheidung schützt vor überzogenen Erwartungen. Eine KI zur Prüfungsanmeldung wird nie "mitdenken", sondern nur vordefinierte Muster abbilden.
Lernparadigmen: Wie KI lernt
Maschinelles Lernen (ML) lässt sich in drei grundlegende Paradigmen unterteilen:
Überwachtes Lernen
Modelle werden mit gelabelten Daten trainiert – also mit Eingaben, denen jeweils ein erwarteter Ausgabewert zugeordnet ist. Ziel ist es, neue Eingaben korrekt vorherzusagen. Während des Trainingsvorgangs entwickelt der Algorithmus Funktionen, die immer besser in der Lage sind, für neue, noch nicht gesehene Daten den erwarteten Wert zu bestimmen.
📌 Beispiel: Vorhersage des Studienerfolgs auf Basis historischer Leistungsdaten.
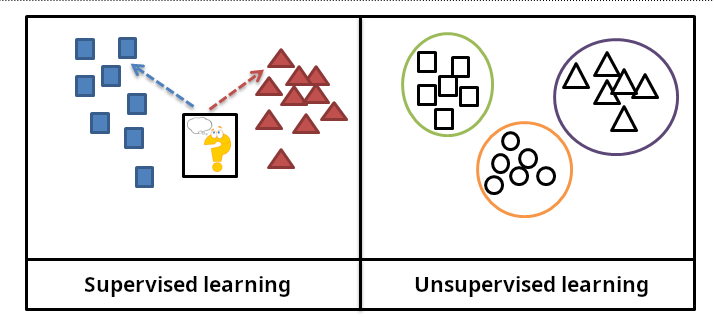
Unüberwachtes Lernen
Hier arbeiten Modelle mit ungelabelten Daten. Algorithmen identifizieren Muster, Gruppen oder Strukturen selbstständig (z.B. Interessen, Fächer oder Zahlenwerte). Während des Trainingsvorgangs lernen Algorithmen Beziehungen zwischen diesen Daten: Gemeinsamkeiten und Unterschiede.
📌 Beispiel: Clusterbildung von Studierenden nach Interessen zur Empfehlung personalisierter Lerninhalte. Das heißt: Studierende werden anhand ihrer übereinstimmenden oder sich unterscheidenden Interessen gruppiert. Sie können dann Lerninhalte aus der Interessengruppe, zu der sie gehören, empfohlen bekommen, die sie bisher nicht selbst angegeben haben.
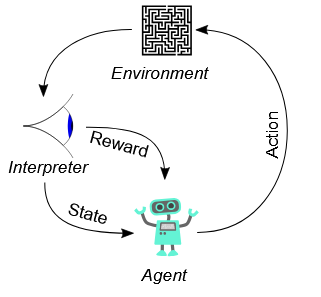
Bestärkendes Lernen (Reinforcement Learning)
Ein sogenannter Agent interagiert mit einer Umgebung, probiert Aktionen aus und lernt über Belohnungen oder Strafen. Ziel ist es, Strategien zu entwickeln, die langfristig die höchste Belohnung bringen. Training und Anwendung lassen sich nicht immer so sauber trennen wie beim überwachten und unüberwachten Lernen, sondern ergeben sich aus der Interaktion des Agenten mit der echten Welt: Zu Beginn werden zufällige Handlungen ausprobiert, man spricht von Erkunden (engl. exploration). Sobald der Agent gelernt hat, was funktioniert, konzentriert er sich zunehmend auf Handlungen, die mehr Lohn versprechen, man spricht von Ausnutzen (engl. exploitation).
📌 Beispiel: Lernpfadgenerator. Ein Agent wählt Themen/Konzepte für Lernpfade von Studierenden aus und erhält je nach deren Erfolg oder Misserfolg Belohnung oder Strafe.
Mischformen und Kombinationen
Neben den klassischen Paradigmen gibt es Mischformen:
-
Halbüberwachtes Lernen: Nur ein Teil der Daten ist gelabelt. Das Modell lernt zunächst an diesen, vergibt dann automatisch Labels für die übrigen.
-
Selbstüberwachtes Lernen: Das Modell erzeugt durch Algorithmen Trainingsdaten (Labels) selbst.
- Transferlernen: Ein vortrainiertes Modell, das z.B. schon gut darin ist, Bilder zu erkennen, wird für eine neue, spezialisierte Aufgabe weiterverwendet, um etwa Bilder noch besser zu kategorisieren.
Beim Training vieler Verfahren kommen Kombinationen zur Anwendung. Z.B. besteht das Training von Chat-Assistenten wie ChatGPT aus mehreren Schritten. Im Vortraining wird aus sehr großen Textmengen durch selbstüberwachtes Lernen ein grundlegendes Sprachverständnis entwickelt.
Im anschließenden Feintuning werden Modelle mit typischen Dialogbeispielen konfrontiert, um zu lernen, wie Konversationen funktionieren. Und in einem weiteren Schritt kann bestärkendes Lernen mit Live-Feedback von Menschen verwendet werden, um Antworten zu bewerten, was die Konversationsfähigkeit weiter verbessert.
Hier eine Übersicht der Lernformen und der ihnen zugrundeliegenden Muster sowie Beispiele aus dem Hochschulkontext:
|
Lernform |
Mechanismus |
Hochschul-Beispiel |
|
Überwachtes Lernen |
Lernen aus gelabelten Daten |
Studienerfolg prognostizieren |
|
Unüberwachtes Lernen |
Lernen aus ungelabelten Daten |
Forschungsdaten thematisch clustern |
|
Bestärkendes Lernen |
Belohnung für erfolgreiche Aktion |
Energiemanagement in Campus-Gebäuden optimieren |
|
Selbstüberwachtes Lernen |
selbständiges Labeln und Lernen von Strukturen |
Training generativer Sprachmodelle wie ChatGPT mit öffentlichen Texten |
💡 Lernzusammenfassung Kapitel 1.2: KI-Typen
- Schwache vs. starke KI: Während schwache KI spezifische Aufgaben nach festen Regeln löst, beschreibt starke KI die theoretische Fähigkeit, eigenständig Probleme zu erkennen und kreativ zu lösen – ein Ideal, das aktuell noch nicht erreicht ist.
- Lernparadigmen in der KI: Maschinelles Lernen erfolgt z. B. überwacht (mit Labels), unüberwacht (ohne Labels) oder bestärkend (mit Belohnungssystemen). Moderne KI kombiniert häufig mehrere dieser Paradigmen.
- Superintelligenz, Nick Bostrom
- The Master Algorithm, Pedro Domingos