1.3 Wie Maschinen lernen: Neuronale Netze, Deep Learning und LLMs
1.3 Wie Maschinen lernen: Neuronale Netze, Deep Learning und LLMs
Wie lernen Maschinen eigentlich? Neuronale Netze bilden das Gehirn moderner KI – faszinierend und mächtig zugleich.
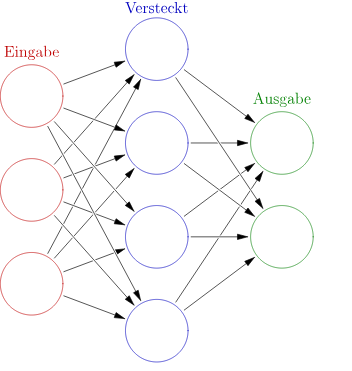
Neuronale Netze orientieren sich am Aufbau des menschlichen Gehirns: Sie bestehen aus zahlreichen künstlichen "Neuronen", die über sogenannte Kanten miteinander verbunden sind. Diese Netze sind in Schichten organisiert:
|
|
In dieser Grafik gibt es nur eine versteckte Schicht. Aber tiefe neuronale Netze (Deep Neural Nets) bestehen aus vielen Schichten versteckter Neuronen. Je nach Architektur können auch die Verbindungsmuster von Neuronen sehr verschieden aussehen. |
Architekturen: Wie Informationen fließen
|
|
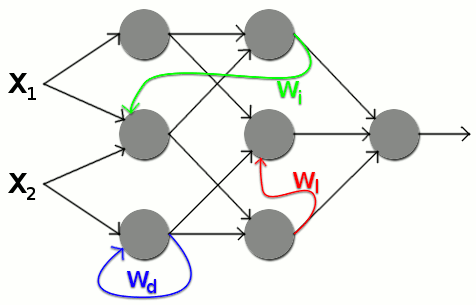
In einfachen Netzen fließen Informationen nur in eine Richtung – von Eingabe zu Ausgabe. Sie sind miteinander verknüpft. Diese Verbindungen nennt man auch Kanten. Während einfache neuronale Netze nur Vorwärtskanten haben, haben z.B. rekurrente Netze auch Rückkanten, durch die Neuronen auf vorherige Schichten Einfluss nehmen können. Damit können auch Kontextbezüge oder zeitliche Abhängigkeiten gelernt werden. |
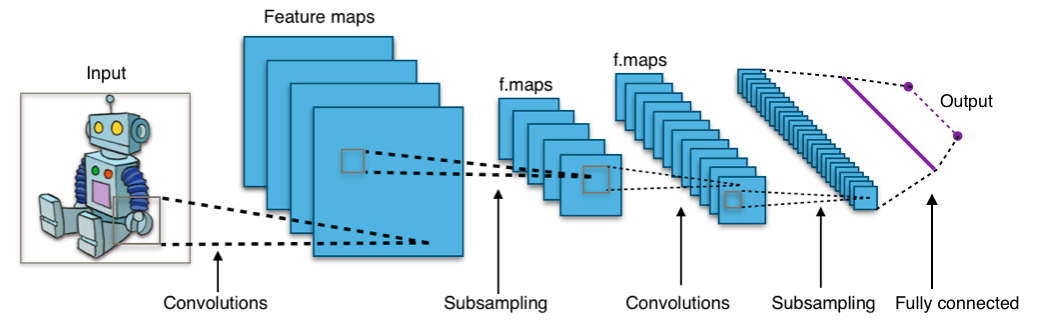
Spezialisierte Architekturen wie Convolutional Neural Networks (CNNs) sind in der Lage, mehrdimensionale Eingaben wie Bilder oder Videos effizient zu verarbeiten.
Informationsverarbeitung: Gewichte und Lernen
Zwischen den Neuronen wirken Gewichte, die bestimmen, wie stark ein Signal weitergegeben wird. Diese Gewichte – auch Parameter genannt – werden beim Training des Netzwerks angepasst. Sie spiegeln das Wissen wider, das das Modell durch Lernen erworben hat.
Je nach Gewicht reagiert das Netz unterschiedlich stark auf bestimmte Eingaben und entscheidet so z. B., ob ein Bild eher als "Hund" oder "Katze" interpretiert wird.
Wie kommen wir zu einem Modell, das ein Problem löst?
|
|
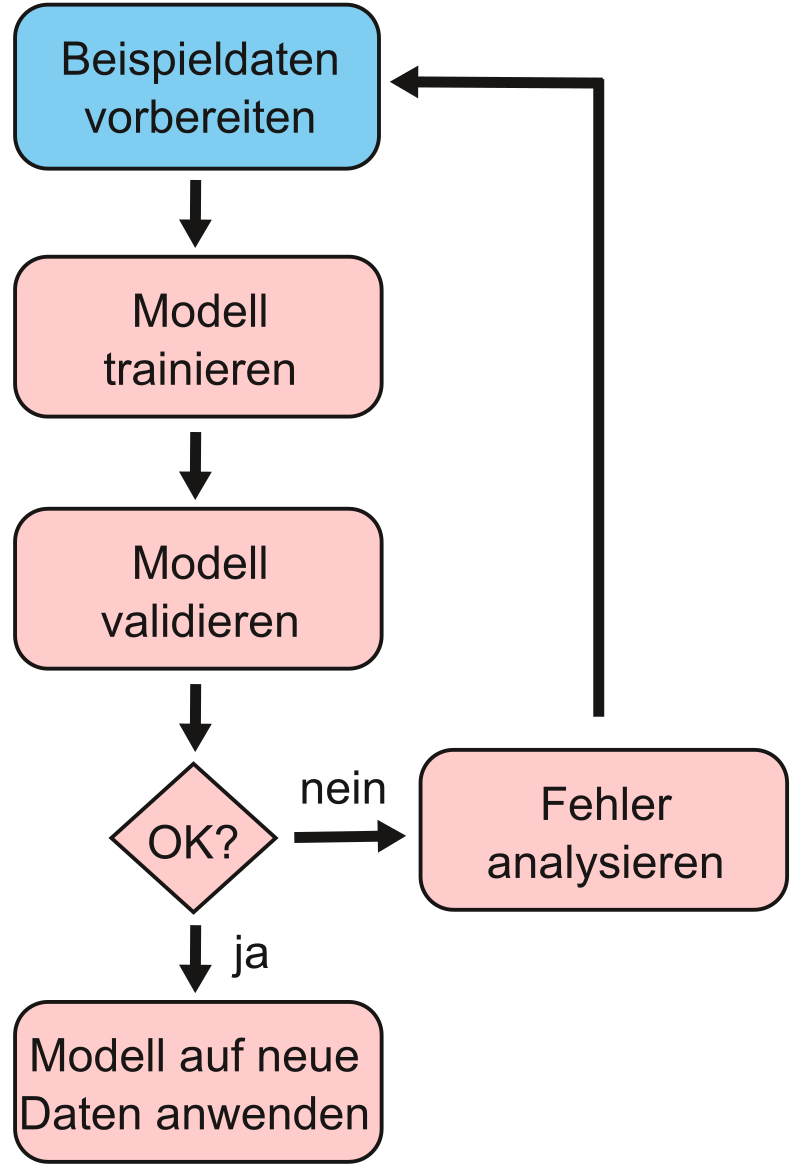
Ein Beispiel aus der Praxis: Wir wollen ein Modell bauen, das Hunde- und Katzenbilder unterscheidet – ein Klassifikationsproblem. Dazu nutzen wir ein neuronales Netz mit überwachtem Lernen und gelabelten Daten (Bilder mit eindeutigen Labels). Da für Bildklassifizierungen neuronale Netze besonders geeignet sind, verwenden wir für dieses Problem genau dieses und haben im Sinne der Five Tribes nach Domingos einen konnektivistischen Ansatz gewählt. Um ein Klassifikationsproblem zu lösen, können wir von diesem vereinfachten Phasenmodell ausgehen: Vorbereiten, Training, Test und Anwendung |
{kind=link}
{kind=link}
Vorbereiten: Datenakquisition und Splitting
Wir sammeln 2500 Bilder von Hunden und 2500 Bilder von Katzen. Um diese Bilder zu labeln, haben wir verschiedene Optionen: Wir könnten die Bilderrahmen in einer separaten Tabelle in einer Spalte sammeln und in einer zweiten Spalte das Label "Hund" oder "Katze" vermerken. Wir könnten das Label auch in jedem Bildernamen unterbringen: z. B. Katze1.png, Katze2.png,… Hund1.png,… Am einfachsten ist aber, die Bilder einer Kategorie jeweils in einem Ordner mit dem Labelnamen zu speichern – also alle Hundebilder in einem Ordner "Hund" und alle Katzenbilder in einem Ordner "Katze".
Für die nachfolgenden Schritte teilen wir die Bilder in drei Gruppen auf: 1000 Bilder halten wir für das Testen zurück. Von den übrigen 4000 Bildern verwenden wir 3500 für das konkrete Training und 500 für die Validierung. Wir kommen gleich dazu, was das bedeutet. Beim Splitten ist es wichtig, dass wir möglichst gleiche Anzahlen der Klassen (also jeweils gleiche Anzahl von Bildern mit Hunden und Katzen) in den jeweiligen Teilmengen beibehalten.
So läuft das Training ab
Das Training läuft in Schritten ab. Im Fall von neuronalen Netzen sprechen wir von Epochen und Batches. Pro Epoche werden einmal alle 3500 Trainingsbilder durch das neuronale Netz geschleust. Eine Epoche läuft in Batches ab. Pro Batch werden z. B. jeweils 50 Bilder einzeln als Eingabe in das Netzwerk gegeben und vorwärts durch das Netz geschickt oder propagiert (engl. forward propagation).
Dadurch ergibt sich ein Ergebniswert, also eine jeweilige Prognose des aktuellen Netzes hinsichtlich der Frage, ob auf dem jeweiligen Bild ein Hund oder eine Katze abgebildet ist. Diese Ausgabe wird mit dem gewünschten Ergebnis entsprechend der bekannten Labels (Ordnernamen) der Bilder verglichen.
Die Differenz der beiden Werte nennt man Fehler. Der mittlere Fehler des aktuellen Batches wird anschließend verwendet, um rückwärts, also von der Ausgabeschicht in Richtung Eingabeschicht zurück, zu propagieren (engl. backpropagation). Dabei werden die Gewichte der Neuronenverbindungen so angepasst, dass der Fehler für diese Bilder im nächsten Schritt kleiner wird. Um die genaue Anpassung der Gewichte zu bestimmen, kommen Optimizer wie Stochastic Gradient Descent (Stochastischer Gradientenabstieg) oder der Adam Optimizer zum Zuge.
Durch diesen Prozess lernt das Modell sukzessive aus den Farb-, Helligkeits- und Kontrastinformationen auf den Bildern, wie wohl ein Hund oder eine Katze aussieht.
Dieses Verfahren wird für alle Batches wiederholt, bis das Netzwerk einmal alle 3500 Trainingsbilder "gesehen" hat.
Das ist die Validierung
Nach jeder Epoche wird die jeweilige Leistung des Netzwerks anhand der 500 Validierungsbilder bestimmt: z. B. durch die Genauigkeit, also die richtig zugeordneten Bilder in Relation zur Gesamtzahl der Bilder. Wir können daran sehen, wie sich die Genauigkeit nach jeder Epoche entwickelt und ob das Trainingssetup insgesamt funktioniert oder nicht.
Funktioniert es nicht wie gewünscht, kann man sogenannte Hyperparameter anpassen: Das kann z. B. die Architektur des verwendeten neuronalen Netzes sein, aber auch die Batch-Größe, die Anzahl Epochen oder auch die Lernrate, die bestimmt, wie stark die Gewichte nach jedem Batch entsprechend des Fehlers bei der Rückpropagierung angepasst werden.
Nach dem Training folgt der Test
Am Ende erfolgt die Prüfung auf den 1000 Testbildern – um zu sehen, ob das Modell auch auf neue Daten zuverlässig reagiert.
Der Test auf Bilder, die das Modell noch nie gesehen hat, ist wichtig, um zu prüfen, ob wir ein Modell haben, das auch für den allgemeinen Fall geeignet ist. Es ist möglich, dass ein Modell im Training trotz Validierung die Daten zu genau oder sogar "auswendig" lernt – inklusive Fehlern (Overfitting).
Es ist auch umgekehrt möglich, dass das Modell systematische Unterschiede der Testbilder irrtümlich als zentrale Unterscheidungsmerkmale interpretiert. Ein Beispiel wäre, dass Hunde in den Trainingsbildern überproportional häufig ein Halsband tragen würden. Das Modell könnte dann versehentlich daraus schließen, dass vor allem das Halsband bedeutet, dass ein Bild einen Hund darstellt.
📌Anwendungsbeispiel: Ein Modell mit z. B. 85 %+ Genauigkeit kann in einem Webservice zur Tierbildklassifikation eingebunden werden.
Modellpflege: Wenn Training nicht reicht
Systematische Datenprobleme können sich schon vor dem Splitten der Daten eingeschlichen haben. Es könnte z. B. sein, dass die Katzenbilder systematisch heller sind als die Hundebilder, damit würde das Modell ggf. nur lernen, dass helle Bilder Katzen darstellen und dunklere Bilder Hunde. Daher ist eine Überwachung der Modellleistung auch während der Anwendung noch relevant.
Diese Überwachung ist nicht nur erforderlich, um solche systematischen Fehler aufzudecken, sondern auch, um Veränderungen in den Daten Rechnung zu tragen, die Nutzende für Vorhersagen liefern. Diese Veränderungen könnten entstehen, indem neue Hunde- oder Katzenrassen in den Anwendungsdaten auftauchen, die bisher nicht in Trainings-, Validierungs- oder Testdaten enthalten waren. Das bezeichnet man als Model-Drift und kann ein erneutes Training mit einem aktualisierten Datensatz erforderlich machen.
Moderne neuronale Netze und wie sie Sprache verstehen
Die heute dominierende Architektur ist der Transformer. Sie wurde 2012 eingeführt und funktioniert über den sogenannten Self-Attention-Mechanismus: Dieser erlaubt es der KI, bei der Verarbeitung einer Eingabe (z. B. einem Satz) zu erkennen, wie stark jedes Element (z. B. ein Wort) mit allen anderen Elementen zusammenhängt. Die Fähigkeit, kontextuelle Zusammenhänge über lange Texte hinweg effizient zu verarbeiten, macht Transformer (im Gegensatz zu rekurrenten Netzen, RNNs) zur Grundlage für Modelle wie Generative Pre-trained Transformer (GPT). Denn sie sind ideal für Sprache und die Basis für heutige Large Language Models (LLMs) wie ChatGPT, LLaMA oder DeepSeek.
LLMs mit Unmengen an Daten trainiert
LLMs werden mit gigantischen Textmengen trainiert. Konkret waren das z. B. im Falle des quelloffenen DeepSeek LLM mit 67 Milliarden Parametern 2 Billionen Tokens (~Wortteile, s. nächster Abschnitt). Nimmt man an, dass 1 Token in etwa 0,75 Wörtern entspricht und wir 333 Tokens pro Seite (= 250 Wörter) haben, entspricht das 6 Milliarden Buchseiten oder 10 Millionen Büchern à 600 Seiten.
Wenn ein Token ca. 4 Bytes hat, entspricht das in etwa 7,5 Terabytes an Textdaten. Für das größere Modell von DeepSeek mit 671 Milliarden Parametern wurden sogar 14,8 Billionen Tokens an Trainingsdaten verwendet. Für die Modelle LLaMA 3.1 von Meta waren es 15,6 Billionen und für Qwen2.5 von Alibaba 18 Billionen Tokens.
Aufgrund der Größe der Modelle und der verwendeten Trainingsdatenmenge erklärt sich dann auch, warum das Training so große Rechenzentren mit vielen hunderten GPUs (graphics processing units, Grafikprozessoren) benötigt, dennoch Wochen dauert und daher so teuer und energieaufwendig ist.
Wieso verstehen LLMs uns überhaupt?
Für das Training von LLMs wird Text in sogenannte Tokens umgewandelt. Das sind kleinste Bedeutungseinheiten der Sprache wie Wörter, Teilwörter, Wortteile oder Satzzeichen. Diesen Tokens wird für das Training eine numerische ID zugeordnet.
Der Beispielsatz "Die Katze schläft." könnte in folgende Tokens zerlegt werden:
["Die", "Kat", "ze", "schläft", "."]
Und diesen Tokens würden entsprechende IDs zugewiesen:
["Die" → 101, "Kat" → 202, "ze" → 203, "schläft" → 204, "." → 205],
was in der ID-Sequenz
[101, 202, 203, 204, 205]
resultieren würde. Diese kann dann in das Modell zum Training eingegeben und verarbeitet werden.
Besonderheiten der Transformer-Architektur und Embeddings
Die Transformer-Architektur und der Self-Attention-Mechanismus sind besonders, weil sie bestimmen, wie mit Text weitergearbeitet wird. Dabei wird berücksichtigt, was vorher und nachher steht, und auch, was das neuronale Netz schon gelernt hat. ID-Tokens werden je nach Kontext unterschiedlich weiterverarbeitet. Das heißt: Tokens werden im Modell in Embeddings überführt – mathematische Vektoren mit semantischer Bedeutung. Doch ein Beispiel zeigt, wie der Kontext mitgedacht wird.
Wir haben diese zwei Sätze:
1. "Ich sitze auf der Bank am Fluss."
2. "Ich habe Geld auf die Bank eingezahlt."
Wir haben zweimal Bank mit unterschiedlicher Bedeutung. Das heißt: Beide haben dieselbe Token-ID, aber unterschiedliche Embeddings – je nach Kontext. So erkennt das Modell verschiedene Bedeutungen desselben Wortes. Transformer-basierte LLMs analysieren die umgebenden Wörter ("am Fluss" vs. "Geld eingezahlt") und generieren für jedes Vorkommen von "Bank" ein spezifisches Embedding, das die jeweilige Bedeutung reflektiert.
Während die ersten Transformer-Schichten vor allem lokale Wortzusammenhänge erfassen (z. B. „am Fluss“ vs. „Geld eingezahlt“ für das Wort „Bank“), verschieben sich die Repräsentationen in den tieferen Blöcken immer stärker in Richtung globaler Semantik. Dort werden nicht nur Wort-Bedeutungen, sondern auch grammatikalische Konstruktionen wie Ko-Referenzen erfasst. Je tiefer die Schicht, desto übergeordneter die Zusammenhänge: Ironie, Argumentationsbögen oder die Stilistik eines Textes. So entstehen Themen- und Diskursstrukturen, die selbst Abhängigkeiten zwischen weit auseinanderliegenden Passagen abbilden. Auf diesen Ebenen fließen Informationen aus dem gesamten Kontext zusammen, sodass das Modell beim Generieren von Antworten auf ein tief integriertes, ganzheitliches Verständnis zugreift.
Die Behauptung, dass LLMs "nur" jeweils das nächste wahrscheinlichste Wort vorhersagen, bleibt dabei im Kern richtig, wird aber der Komplexität des Prozesses nicht gerecht.
Neue Entwicklungen
💡 Lernzusammenfassung Kapitel 1.3: Neuronale Netze, Deep Learning und LLMs
- Neuronale Netze und Deep Learning: Künstliche neuronale Netze bestehen aus vielen Schichten verknüpfter Einheiten. Ihre Lernleistung ergibt sich aus der Anpassung von Verbindungsgewichten im Training. Tiefe Netze (Deep Learning) ermöglichen besonders leistungsfähige Anwendungen.
- Transformer und LLMs: Moderne LLMs basieren auf der Transformer-Architektur mit Self-Attention. Sie verarbeiten große Textmengen über sogenannte Tokens, wandeln diese in kontextbezogene Embeddings um und sind in der Lage, Sprache flexibel zu interpretieren und zu generieren.
- Aktuelle Entwicklungen: Neue Verfahren wie Mixture-of-Experts, Self-Prompting und Chain-of-Thought verbessern Effizienz, Problemlösungsfähigkeit und Nachvollziehbarkeit. Multimodale LLMs integrieren zusätzlich Bild-, Text- und Audioverarbeitung.