Maschinelles Lernen (ML) – Der Motor hinter KI
Maschinelles Lernen (ML) – Der Motor hinter KI
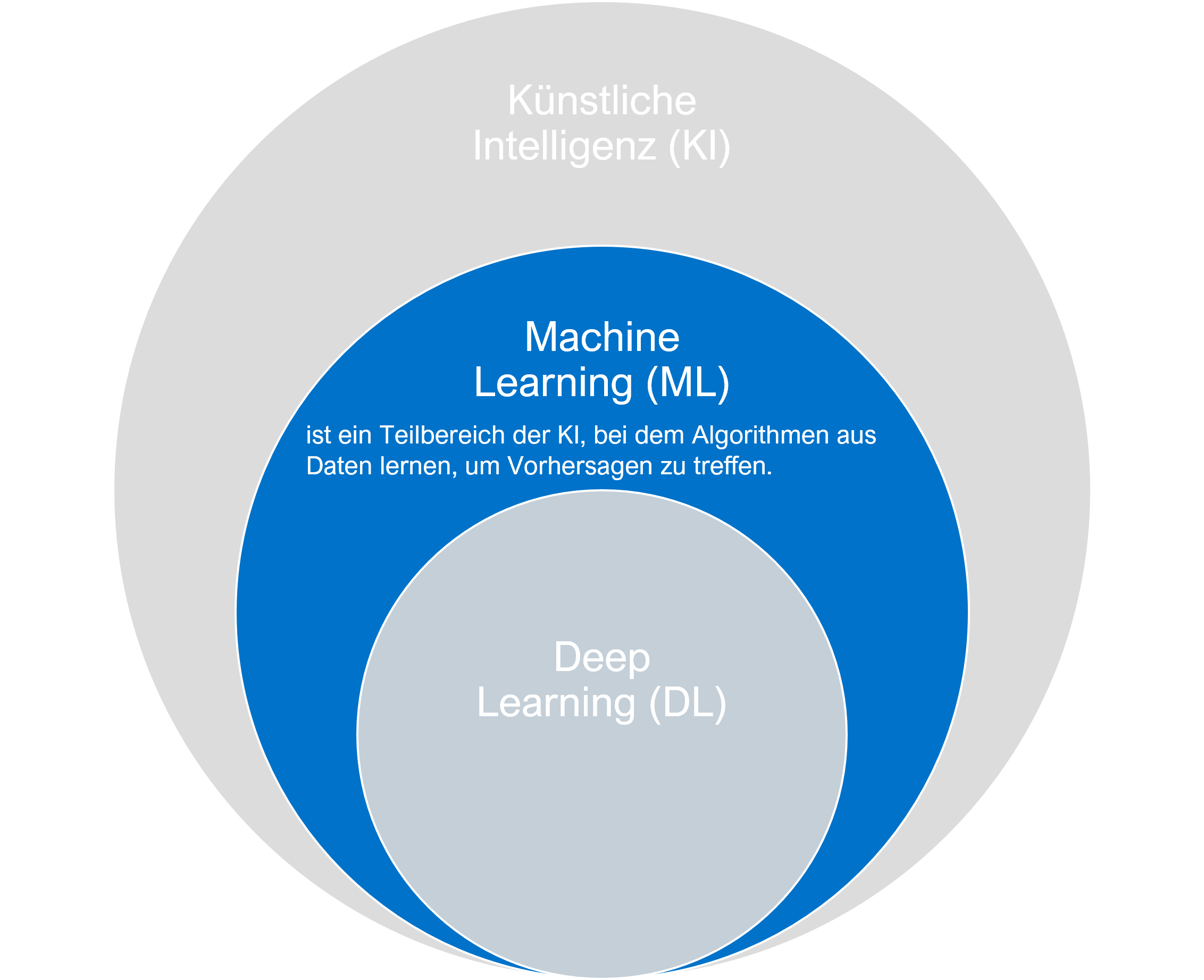
Maschinelles Lernen (ML) ist ein Teilbereich der Künstlichen Intelligenz, der sich damit beschäftigt, wie Computer durch Erfahrungen lernen können, ohne explizit programmiert werden zu müssen. Die Idee hinter Maschinellem Lernen ist es, Algorithmen zu entwickeln, die aus Daten lernen und basierend auf diesem Wissen Vorhersagen oder Entscheidungen treffen können. Während traditionelle Computerprogramme durch festgelegte Regeln und Anweisungen funktionieren, verwenden ML-Modelle Muster und Zusammenhänge in den Daten, um zu lernen und sich zu verbessern.
Es gibt verschiedene Arten des Maschinellen Lernens, die je nach Art der Daten und der Aufgabenstellung angewendet werden. Grundsätzlich unterscheidet man zwischen überwachten, unüberwachten und bestärkenden Lernmethoden. Überwachtes Lernen verwendet gekennzeichnete Daten, um Modelle zu trainieren, die dann neue, ähnliche Daten klassifizieren oder Vorhersagen treffen können. Unüberwachtes Lernen hingegen arbeitet mit unmarkierten Daten, um Muster oder Strukturen zu erkennen. Das bestärkende Lernen basiert auf dem Prinzip der Belohnung und Bestrafung und wird verwendet, um Agenten zu trainieren, die in einer Umgebung Entscheidungen treffen müssen, um ihre Ziele zu erreichen.
Do you want to start at the last page you saw?