- Nutze alle Lernfunktionen, wie Tests, Quizze und Umfragen.
- Schreibe Beiträge und tausche dich in unseren Foren aus.
- In einigen Lernangeboten bestätigen wir dir die Teilnahme.
KI und Diversität
Abschnittsübersicht
-
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Einführung
-
-
Herzlich willkommen zu unserem Lernangebot rund um Künstliche Intelligenz (KI) und Diversität. Ihr lernt über grundlegende Konzepte von KI, erkennt Biases, befasst euch mit ethischen Fragestellungen, lernt Standards vertrauenswürdiger KI kennen und erhaltet Einblicke in Prompting-Techniken. Ziel ist es, dass ihr ein Bewusstsein für Chancen und Risiken entwickelt und KI verantwortungsvoll anwendet.
-
Künstliche Intelligenz (KI) ist allgegenwärtig – von Sprachassistenten über Bilderkennung bis hin zu Empfehlungssystemen auf sozialen Plattformen prägt sie unseren Alltag. Doch was verbirgt sich hinter Begriffen wie Künstliche Intelligenz (KI), Maschinelles Lernen (ML), Deep Learning und Natural Language Processing (NLP)? Bevor wir tiefer in die Materie eintauchen, klären wir zunächst diese grundlegenden Konzepte.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
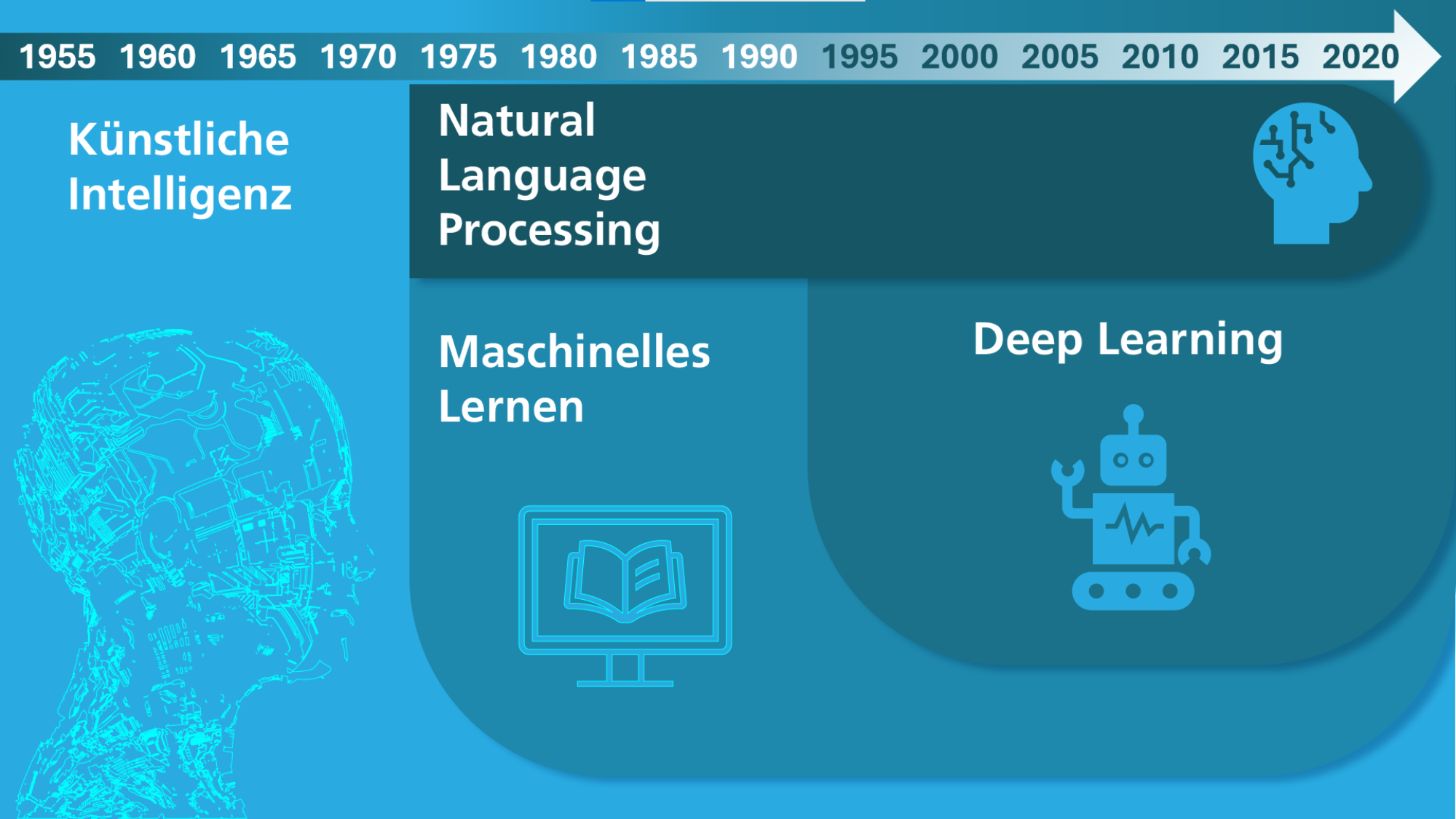
KI-Historie von Fraunhofer IAIS (CC BY-SA 4.0) -
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Künstliche Intelligenz (KI) ist ein Teilgebiet der Informatik, und befasst sich damit, wie ein Computer intelligentes, menschliches Verhalten nachahmen kann. Dabei ist weder festgelegt, was »intelligent« bedeutet, noch welche Technik zum Einsatz kommt. Eine der Grundlagen der modernen KI ist das Maschinelle Lernen.
Machine Learning (Maschinelles Lernen): Durch selbst lernende Algorithmen analysieren Computerprogramme Datensätze und erkennen Muster und Gesetzmäßigkeiten, ohne dafür explizit programmiert zu sein. Es wird als ein Teilgebiet der KI definiert, wobei diverse Ansätze, einschließlich tiefen neuronalen Netzen, eingesetzt werden. Im Gegensatz zur (subsymbolischen) KI, die auf die Nachahmung von Gehirnfunktionen ausgerichtet ist, beruht maschinelles Lernen darauf, Modelle automatisch zu optimieren, indem Trainingsdaten analysiert und daraus Erkenntnisse gewonnen werden. Maschinelles Lernen (ML) kommt unter anderem in Spam-Filtern zum Einsatz, wo Algorithmen wie Naive Bayes unerwünschte E-Mails automatisch erkennen. Auch in der dynamischen Preisgestaltung wird ML genutzt, um Preise in Echtzeit basierend auf Angebot und Nachfrage anzupassen. In der Sportanalyse helfen Methoden wie Regression oder k-nearest neighbors dabei, die Leistung von Spielern vorherzusagen oder taktische Entscheidungen zu unterstützen.
Deep Learning beschreibt die Umsetzung eines maschinellen Lernverfahrens in Form eines künstlichen neuronalen Netzes. Die Erzeugung der relevanten Merkmale für das Lernen erfolgt selbsttätig. Künstliche neuronale Netze, inspiriert von neuronalen Netzwerken des menschlichen Gehirns, sind zentrale Komponenten des Deep Learning. Sie bestehen aus mehreren Neuronen, auch Units genannt, die Informationen aus der Umwelt oder von anderen Neuronen aufnehmen und diese in modifizierter Form an andere Units oder die Umwelt weiterleiten. Die Units sind durch Kanten miteinander verbunden, wobei die Stärke der Verbindung zwischen zwei Neuronen durch ein Gewicht ausgedrückt wird. Wissen wird in diesen Gewichten gespeichert, und Lernen erfolgt durch schrittweise Gewichtsveränderungen.
Die Struktur der neuronalen Netze umfasst verschiedene Typen von Units:
- Input Units: Diese nehmen die notwendigen Informationen auf, verarbeiten die verwendeten Daten und geben sie mit einem Gewicht an die nächste Schicht weiter.
- Hidden Units: Diese Schicht(en) befindet sich zwischen den Input und Output Units. Hier können beliebig viele Neuron-Ebenen verwendet werden. Die empfangenen Informationen werden erneut gewichtet und von Neuron zu Neuron an die Output Units weitergereicht. Die genaue Prozessierung der Informationen in den Hidden Units bleibt dabei undurchsichtig und wird oft als Black Box bezeichnet.
- Output Units: Diese bilden die letzte Ebene des Netzes und schließen unmittelbar an die Hidden Units an. Die Output-Neuronen enthalten die resultierenden Entscheidungen.
Insgesamt ermöglichen künstliche neuronale Netze eine komplexe Verarbeitung von Informationen durch die dynamische Anpassung der Gewichtungen zwischen den Neuronen, wodurch sie in der Lage sind, aus Daten zu lernen und Entscheidungen zu treffen.
Praxisbeispiele für Deep Learning und neuronale Netze
1. Bilderkennung in der Medizin
- Deep-Learning-Modelle werden genutzt, um Röntgen- oder MRT-Bilder zu analysieren und Anomalien wie Tumore zu identifizieren.
- Beispiel: Ein neuronales Netz wird mit tausenden Bildern trainiert, um Krebszellen von gesunden Zellen zu unterscheiden
2. Autonomes Fahren
- Sensoren in autonom fahrenden Autos liefern Daten an ein neuronales Netz, das Objekte erkennt (z. B. Fußgänger, Verkehrsschilder) und darauf reagiert.
- Die Deep-Learning-Modelle lernen aus Millionen von Straßenaufnahmen, wie Personen Entscheidungen treffen.
3. Betrugserkennung im Finanzwesen
- Banken nutzen Deep Learning, um betrügerische Transaktionen zu erkennen.
- Ein neuronales Netz analysiert Zahlungshistorien und warnt bei ungewöhnlichen Transaktionen
Natürliche Sprachverarbeitung (Natural Language Processing, NLP) ist ein Teilgebiet der KI und beschäftigt sich mit der Interaktion zwischen Computern und menschlicher Sprache. Das Ziel von NLP ist es, Maschinen zu ermöglichen, gesprochene und geschriebene Sprache zu verstehen, zu interpretieren und zu generieren. NLP kombiniert Methoden aus der Informatik, der Linguistik und dem maschinellen Lernen, um komplexe sprachbezogene Aufgaben zu bewältigen.
NLP profitiert auch von Fortschritten im Bereich des Deep Learning, insbesondere durch den Einsatz neuronaler Netze, die Sprach- und Fundamentalmodelle auf Basis großer Datenmengen trainieren. Dabei kommen mehrschichtige neuronale Netze (Deep Learning) zum Einsatz, die es ermöglichen, semantische und syntaktische Strukturen in Texten zu erfassen.
Wichtige Anwendungsbereiche von NLP
- Intelligente Übersetzung: Systeme wie DeepL nutzen NLP-Algorithmen, um Texte automatisch von einer Sprache in eine andere zu übersetzen.
- Sprachassistenzsysteme: Virtuelle Assistenten wie Siri, Alexa oder Google Assistant basieren auf NLP-Ansätzen, um Benutzereingaben zu verstehen und passende Antworten zu generieren.
- Textanalyse und Sentimentanalyse: Unternehmen nutzen NLP zur automatischen Analyse von Kundenbewertungen oder Social-Media-Beiträgen, um Meinungen und Stimmungen zu extrahieren.
- Automatische Textgenerierung: Anwendungen wie Chatbots oder Nachrichtengeneratoren nutzen NLP-Methoden, um kohärente und relevante Texte zu verfassen.
- Informationsgewinnung: NLP ermöglicht es, aus großen Textmengen automatisch relevante Informationen zu extrahieren, z. B. in der medizinischen Diagnostik oder im juristischen Bereich.
Technologische Grundlagen von NLP
- Tokenization: Aufspaltung eines Textes in kleinere Einheiten (Wörter oder Sätze).
- Part-of-Speech-Tagging: Bestimmung der Wortart eines Begriffs im Kontext eines Satzes.
- Named Entity Recognition (NER): Identifikation von Eigennamen, Orten oder Organisationen in einem Text.
- Syntax- und Semantikanalyse: Untersuchung der grammatikalischen Struktur und der inhaltlichen Bedeutung eines Satzes.
- Word Embeddings: Repräsentation von Wörtern als Vektoren in einem semantischen Raum, um Bedeutungsähnlichkeiten abzubilden (z. B. Word2Vec, GloVe, BERT).
Zukunftsperspektiven von NLP
Die Weiterentwicklung von NLP wird durch immer leistungsfähigere neuronale Netzwerke und große Sprachmodelle wie GPT oder BERT, sogenannten Transformer-Architekturen, vorangetrieben. In Zukunft könnte NLP noch präzisere und menschenähnliche Interaktionen ermöglichen, wodurch es in immer mehr Anwendungsfeldern eine zentrale Rolle spielen wird. Herausforderungen wie die Erkennung von Ironie, die Berücksichtigung von Kontext oder die Reduzierung von Vorurteilen in Trainingsdaten bleiben jedoch bestehen und sind Gegenstand aktueller Forschung.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
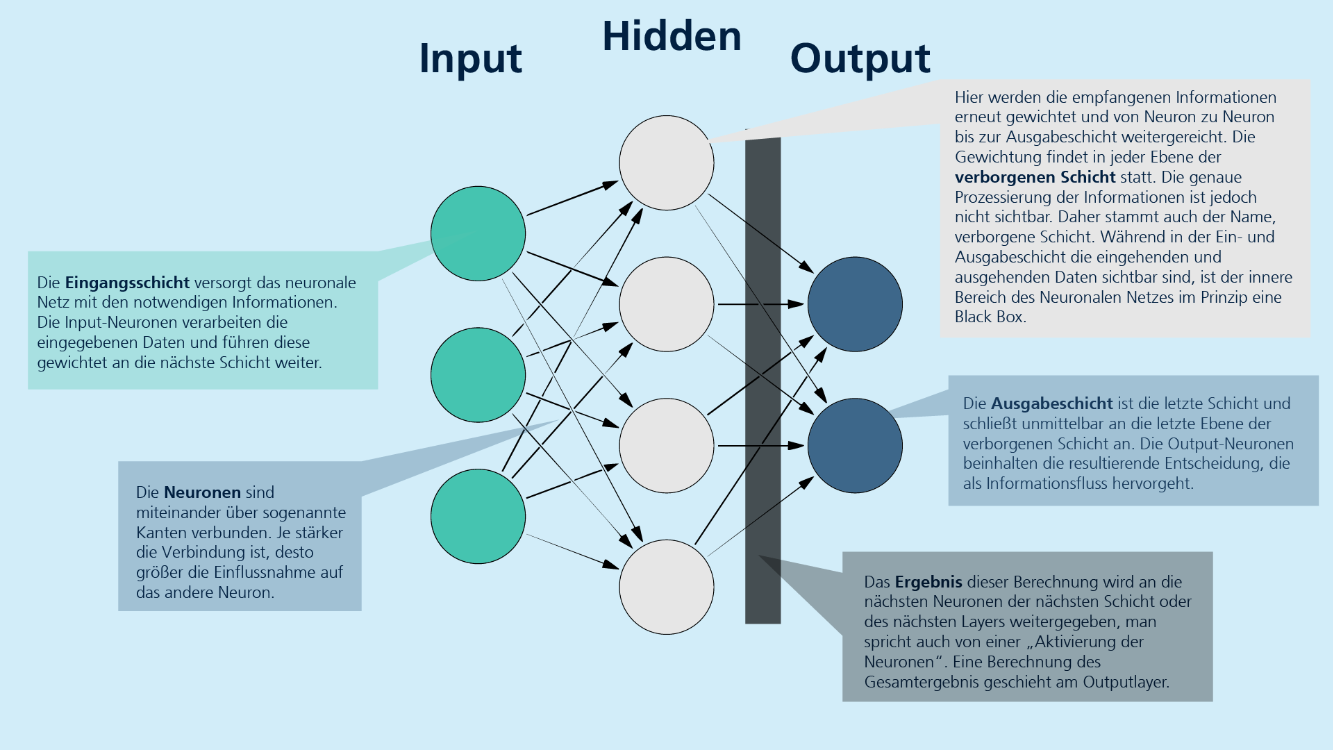
Aufbau von künstlichen Neuronalen Netzen von Fraunhofer IAIS (CC BY-SA) -
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenTool-Liste: 🔨
Neuronale Netze einsteigerfreundlich selbst programmieren:
Neuronale Netze ohne Coding trainieren:
NLP und Sprachmodelle verstehen:
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
KI-Systeme sind nicht neutral: Verzerrungen in Daten und Algorithmen können zu unfairen oder diskriminierenden Entscheidungen führen – doch welche Arten von Bias gibt es, und wie entstehen sie?
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenArten von Biases
Die Dimensionen von Diversität, wie ethnischer Hintergrund, Geschlecht, Alter, sexuelle Orientierung, Religion, soziale Herkunft sowie körperliche und geistige Fähigkeiten, prägen die Vielfalt innerhalb einer Gesellschaft. Diese Aspekte beeinflussen maßgeblich, wie Menschen leben und miteinander interagieren. Das Ziel von Diversitätsförderung ist es, eine Gesellschaft zu schaffen, in der alle Menschen gleiche Chancen und Rechte genießen. Chancengleichheit, die Innovationskraft durch verschiedene Perspektiven sowie die Förderung von Inklusion sind hierbei zentrale Elemente. Ein respektvoller interkultureller Dialog spielt ebenso eine wichtige Rolle, um gesellschaftliche Kohäsion zu fördern und eine offene sowie gerechte Gemeinschaft zu schaffen.
In einer zunehmend digitalisierten Welt beeinflussen diese Dimensionen der Diversität jedoch auch die Technologieentwicklung, insbesondere im Bereich der KI. Ein Bias, oder eine systematische Verzerrung in der Wahrnehmung, im Denken oder in der Entscheidungsfindung, kann in KI-Algorithmen (unbewusst) eingebaut sein. Solche Verzerrungen führen dazu, dass Informationen selektiv interpretiert oder bewertet werden, was zu inkorrekten und potenziell diskriminierenden Bewertungen führen kann. Im Rahmen des maschinellen Lernens ist es wichtig, zwischen direkter Bias-Wirkung (Disparate-Impact) und indirekte Beziehungen (Disparate Treatment) zu unterscheiden, da der Einsatz von KI- Algorithmen nicht automatisch Bias-Effekte vermeidet. Die Algorithmen müssen genau auf die jeweilige Situation abgestimmt werden. Selbst wenn sensible Attribute wie Alter, Religionszugehörigkeit oder Geschlecht aus den Daten entfernt werden, können Algorithmen, die auf diesen Daten trainiert werden, dennoch ungewollte diskriminierende Inhalte produzieren.
Bias-Arten wie bspw. Selektionsbias (durch unausgewogene Trainingsdaten), Bestätigungsbias (Verstärkung von Vorurteilen durch Algorithmen) und historischer Bias (veraltete Daten, die Diskriminierung abbilden) werden in der Literatur unterschiedlich definiert.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenUrsachen & Auswirkungen von Biases in Datensätzen und im Training von Modellen
Diskriminierung in KI-Systemen kann durch verschiedene Ursachen bedingt sein.
Häufige Ursachen für Biases
- In den Trainingsdaten:
- Historische Ungleichheiten werden reflektiert und verstärkt.
- Fehlende oder unausgewogene Daten sorgen für eine verzerrte Repräsentation.
- Sensible Merkmale können auch indirekt über Proxy-Attribute Einfluss nehmen.
- Im Modell selbst:
- Programmierte Entscheidungsregeln können unbeabsichtigt diskriminierende Auswirkungen haben.
- Entwickler*innen übertragen unbewusst Stereotype oder gesellschaftliche Vorurteile auf das Modell. Neuronale Netze und andere komplexe Modellarchitekturen agieren oft als "Black Boxes", bei denen es schwierig ist, die genauen Entscheidungswege nachzuvollziehen. Gewichtsanpassungen und versteckte Schichten können dazu führen, dass Verzerrungen unbewusst in den Entscheidungsprozess eingeführt werden, ohne dass Entwickler*innen dies erkennen.
- Während der Modellanwendung und -optimierung:
- KI-Modelle, die sich kontinuierlich weiterentwickeln, können unbeabsichtigt Diskriminierung verstärken.
- Fehlende Audits oder menschliche Kontrollinstanzen können dazu führen, dass diskriminierende Entscheidungen nicht erkannt oder korrigiert werden.
Diskriminierung in KI-Systemen kann auf verschiedene Weise zum Vorschein kommen, insbesondere in Bereichen wie Gesichtserkennung, Arbeitsmarkt, Kreditvergabe und Gesundheitswesen. Bei der Gesichtserkennung zeigen sich Probleme wie eine schlechte Erkennung von dunkelhäutigen oder weiblichen Menschen, was zu diskriminierenden Ergebnissen in Anwendungen wie dem Entsperren von Smartphones oder der Strafverfolgung führt. Im Arbeitsmarkt können KI-gestützte Systeme zur Vorsortierung von Bewerbungen Diskriminierung aufgrund von Alter, Geschlecht oder ethnischer Herkunft fördern. Ähnliche Probleme bestehen bei der automatischen Einschätzung der Kreditwürdigkeit, wo ebenfalls Alters- und Geschlechtsdiskriminierung auftreten kann. Im Gesundheitsbereich sind Gesundheits-Apps gelegentlich nicht ausreichend auf die Bedürfnisse unterrepräsentierter Gruppen zugeschnitten, was zu einer Geschlechterlücke in den Daten und unzureichender Berücksichtigung spezifischer medizinischer Probleme führen kann.
Um KI gerechter zu gestalten, braucht es gezielte Maßnahmen: Diversität in Datensätzen, Fairness-Algorithmen und transparente Entwicklungsprozesse können helfen, Verzerrungen zu reduzieren.
- In den Trainingsdaten:
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen

Gesichtserkennung mithilfe künstlicher Neuronaler Netze von Fraunhofer IAIS (CC BY-SA) -
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenDiversitätssensible Ansätze
Um Bias in KI-Systemen zu minimieren, sind mehrere strategische Ansätze erforderlich, die sowohl technische als auch gesellschaftliche Aspekte berücksichtigen. Ein zentraler Schritt besteht darin, die Diversität in den Datensätzen sicherzustellen. Dies bedeutet, dass alle relevanten Gruppen in den Daten repräsentiert sein müssen, um Verzerrungen zu verhindern und eine faire Grundlage für die Modellbildung zu schaffen. Eine gezielte und breit angelegte Datenerhebung hilft dabei, systematische Ungleichheiten zu vermeiden und sicherzustellen, dass KI-Modelle nicht ungewollt bestehende Diskriminierungen verstärken. Darüber hinaus sollten Fairness-Algorithmen in den Entwicklungsprozess integriert werden. Diese mathematischen Verfahren erkennen und korrigieren Verzerrungen, die in den Modellen entstehen können, und tragen dazu bei, dass die Entscheidungen eines KI-Systems für alle betroffenen Gruppen gleichermaßen gerecht sind. Regelmäßige Audits und eine hohe Transparenz der KI-Systeme sind ebenfalls entscheidend. Ein weiterer wichtiger Aspekt ist die interdisziplinäre Zusammenarbeit bei der Entwicklung von KI-Systemen. Expert*innen bspw. aus den Bereichen Ethik, Recht und Sozialwissenschaften sollten von Anfang an in den Entwicklungsprozess eingebunden werden. Dies gewährleistet, dass die KI-Systeme nicht nur aus einer technischen Perspektive, sondern auch aus sozialen und ethischen Gesichtspunkten betrachtet werden, um unbewusste Vorurteile zu minimieren und den sozialen Verantwortung gerecht zu werden.
Diese ganzheitliche Herangehensweise trägt dazu bei, dass KI-Technologien langfristig fair und verantwortungsbewusst eingesetzt werden. Es ist jedoch wichtig zu betonen, dass KI niemals vollständig frei von Bias sein kann. Da KI-Systeme auf historischen Daten basieren, die menschliche Entscheidungen und gesellschaftliche Strukturen widerspiegeln, sind sie immer in gewissem Maße von bestehenden Vorurteilen und Ungleichgewichten beeinflusst. Auch wenn durch bspw. sorgfältige Auswahl der Daten und den Einsatz von Fairness-Algorithmen Verzerrungen minimiert werden können, bleibt die Möglichkeit von unbeabsichtigten Biases bestehen. KI kann also niemals völlig „neutral“ oder „unvoreingenommen“ sein, doch durch kontinuierliche Überwachung und Anpassung können wir ihre Auswirkungen erheblich reduzieren und den verantwortungsvollen Einsatz sicherstellen. Eine Vertiefung mit Blick auf eine vertrauenswürdige Entwicklung von KI-Modellen findet sich in den Modulen zwei und drei.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenMethoden und Strategien zur Erkennung und Minimierung von Biases für Nutzer*innen
Für KI-Nutzer*innen, die keinen direkten Einblick in Trainingsdaten oder den Entwicklungsprozess haben, stehen primär indirekte Ansätze zur Verfügung, um potenzielle Biases zu erkennen und deren Auswirkungen zu minimieren. Nutzer*innen können sich beispielsweise auf transparente Informationen und unabhängige Prüfberichte der Anbieter stützen – etwa Zertifizierungen, Fairness-Audits oder Evaluierungsberichte, die Aufschluss darüber geben, inwiefern das System auf Verzerrungen getestet wurde. Ebenso können bspw. öffentliche Berichterstattungen oder Diskussionen und Beiträge auf sozialen Plattformen Erkenntnisse über die die Verlässlichkeit und Transparenz der Systeme eines Anbieters liefern. Zudem hilft es, durch eigene Beobachtungen und systematische Tests, wie das Ausprobieren verschiedener Eingaben, Unregelmäßigkeiten in den Ergebnissen zu erkennen (s. Modul 4).
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Praxisübung (Modul 1): Multiple Choice Quizz 💬
-
-
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Einführung in KI-Ethik
Ethik bezeichnet die philosophische Disziplin, die sich mit den grundlegenden Fragen des richtigen und falschen Handelns befasst. Sie untersucht, welche moralischen Prinzipien und Werte das Handeln von Individuen und Gesellschaften leiten sollten. In der modernen Ethik werden diese Fragen oft im Kontext von Gerechtigkeit, Verantwortung, Wohlstand und Gleichheit diskutiert. Im digitalen Zeitalter hat die Ethik zunehmend an Bedeutung gewonnen, insbesondere im Zusammenhang mit der Entwicklung und dem Einsatz neuer Technologien, wie der Künstlichen Intelligenz. Hier stellt sich die Frage, wie KI so gestaltet und genutzt werden kann, dass sie nicht nur effektiv, sondern auch gerecht und inklusiv ist. In diesem Zusammenhang spielt die Qualität der Daten eine entscheidende Rolle für die Leistung von KI-Modellen. Da diese Modelle auf den Daten trainiert werden, können Verzerrungen oder Unvollständigkeiten in den Daten dazu führen, dass KI-Systeme gesellschaftliche Diskriminierungsstrukturen reproduzieren. Solche Verzerrungen können in Form von Sexismus, Rassismus, Klassismus, Ableismus und anderen Vorurteilen auftreten und letztlich zu Formen der Diskriminierung führen. Um sicherzustellen, dass KI ethisch verantwortungsvoll eingesetzt wird, ist es daher unerlässlich, die Daten auf ihre Qualität und Repräsentativität zu überprüfen und sicherzustellen, dass sie keine bestehenden Ungleichgewichte oder Vorurteile widerspiegeln oder sogar verstärken
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Moral Machine
Doch selbst mit einem perfekten Modell, das auf ausgeglichenen Daten trainiert ist und alle Menschen gleich gut und immer zuverlässig erkennt, kann es zu moralischen Problemen kommen: Ein zentrales Dilemma in der KI-Ethik, insbesondere beim Thema autonomes Fahren, wird durch die Moral Machine illustriert, ein Experiment, das untersucht, wie Maschinen moralische Entscheidungen treffen sollten.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
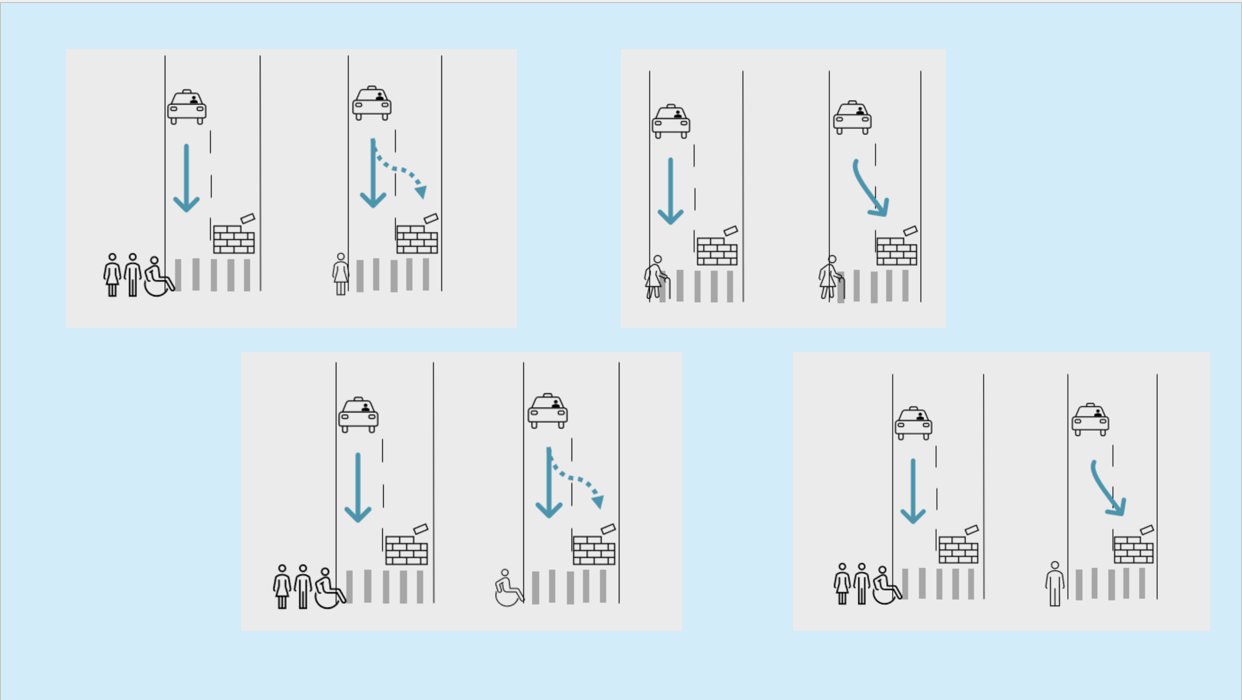
Dilemma der Maschinenethik von Fraunhofer IAIS (CC BY-SA) Bei einem Autounfall, in dem das autonome Fahrzeug entscheiden muss, wer überlebt, stellt sich die Frage, welche Kriterien die Maschine anlegen sollte: Soll sie das Leben des Fahrers oder der Passagiere priorisieren? Oder sollte sie eher das geringste Gesamtopfer wählen, also möglichst viele Leben retten, auch wenn das auf Kosten einer oder mehrerer Personen geht?
In einer solchen Situation steht die Maschine vor einem moralischen Konflikt, der nicht nur von logischen Algorithmen, sondern auch von ethischen Werten abhängt. Während der Mensch häufig durch Intuition und individuelle moralische Vorstellungen entscheidet, muss die KI klare Regeln und Entscheidungen treffen, die in einem breiten gesellschaftlichen Konsens verankert sind. Diese Fragestellungen werfen tiefgreifende ethische und gesellschaftliche Fragen auf: Wer entscheidet, welches Leben wertvoller ist, und wie werden diese Entscheidungen in einer zunehmend von Maschinen gesteuerten Welt getroffen?
Es ist fraglich, ob das System in der gegebenen Situation unterschiedliche Menschen erkennt und entsprechend unterschiedlich handelt, basierend auf ihren spezifischen Merkmalen. Mögliche Merkmalsausprägungen:
- alle Hautfarben
- alle Körperformen
- bestimmte Kleidung
- Menschen im Rollstuhl, mit Krücken etc.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Wie würdest du dich im Falle eines Unfalls entscheiden, bei dem eine Maschine oder ein autonomes Fahrzeug zwischen mehreren möglichen Szenarien wählen muss, wer überlebt?
Teste hier die Moral Machine
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenVerantwortung und Haftung
Wer ist verantwortlich, wenn ein KI-System einen Fehler macht oder Schaden verursacht?
In Deutschland greift – wie bislang – vor allem das bestehende Zivilrecht, insbesondere das Bürgerliche Gesetzbuch (BGB) und das Produkthaftungsgesetz, wenn es um die Haftung im Zusammenhang mit KI geht. Da KI-Systeme keine eigene Rechtspersönlichkeit besitzen, können sie selbst nicht haftbar gemacht werden. Vielmehr ist grundsätzlich derjenige haftbar, der die KI einsetzt, betreibt oder deren Ergebnisse verwendet – etwa Unternehmen, Anbieter oder Entwickler.
Zukünftige Entwicklungen und EU-Initiativen
Die EU-Kommission arbeitet daran, durch neue Regelungsansätze (etwa eine KI-Haftungsrichtlinie) mehr Klarheit und einheitliche Standards zu schaffen. Allerdings ist bislang noch nicht abschließend geklärt, wie diese neuen Regelungen im Detail aussehen und in nationales Recht umgesetzt werden – in einigen Fällen wurden Vorschläge bereits zurückgestellt oder modifiziert.
Weiterführende Links:
§ 823 BGB – Schadensersatzpflicht
https://eur-lex.europa.eu/legal-content/DE/TXT/?uri=CELEX%3A52022PC0496
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
KI Ethik in Europa
Die High-Level Expert Group on Artificial Intelligence (HLEG) wurde 2018 von der Europäischen Kommission ins Leben gerufen, um Empfehlungen zur Politikgestaltung sowie ethische, rechtliche und gesellschaftliche Fragen im Bereich der KI zu erarbeiten. Ziel war es, einen ethischen Rahmen zu schaffen, der sicherstellt, dass KI verantwortungsvoll, transparent und vertrauenswürdig eingesetzt wird. Die von der HLEG entwickelten "Ethik-Leitlinien für eine vertrauenswürdige KI" aus dem Jahr 2019 spielen eine zentrale Rolle in der KI-Ethik-Debatte und haben die Gestaltung des EU AI Acts sowie Zertifizierungsprozesse maßgeblich beeinflusst.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
KI-Ethik in Europa von Fraunhofer IAIS (CC BY-SA) -
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Die ethischen Leitlinien der HLEG haben maßgeblich zur Entwicklung der KI-Verordnung (AI Act) der EU beigetragen, die 2024 verabschiedet wurde und als weltweit erste umfassende Gesetzgebung zur Regulierung von KI gilt. Die Verordnung basiert auf einem risikobasierten Ansatz und zielt darauf ab, Grundrechte, Demokratie und Rechtsstaatlichkeit zu schützen. Darüber hinaus hat die HLEG mit ihren Empfehlungen dazu beigetragen, Zertifizierungsverfahren und Standards für vertrauenswürdige KI zu etablieren (s. Modul 3). Unternehmen werden zunehmend dazu verpflichtet, ihre KI-Systeme auf ethische und rechtliche Konformität zu prüfen, insbesondere wenn sie in sensiblen Bereichen wie dem Gesundheitswesen oder der öffentlichen Verwaltung eingesetzt werden.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Fallstudie (Modul 2)
Gib eine dieser Fallstudien in das Chatfenster ein und diskutiere mit dem Sprachmodell über richtiges und falsches Verhalten. Reflektiere im Anschluss über das System und überlege, ob dieses mit den ethischen Grundsätzen der HLEG konform ist.
Ein großes Technologieunternehmen hat eine KI-gestützte Rekrutierungssoftware entwickelt, die Bewerbungen analysiert und die am besten geeigneten Kandidaten auswählt. Die Software nutzt historische Daten über die bisherigen Einstellungen des Unternehmens, um zukünftige Entscheidungen zu treffen. Das Unternehmen hat in der Vergangenheit eine überwiegend männliche Belegschaft aufgebaut, und die Software spiegelt diese Vorurteile wider. In einer Testphase stellt sich heraus, dass die KI Bewerbungen von Frauen und ethnischen Minderheiten systematisch abweist, weil sie als "weniger passend" eingestuft werden, basierend auf den historischen Daten.
Ein Unternehmen für autonomes Fahren hat ein selbstfahrendes Auto entwickelt, das mit fortschrittlichen Sensoren und Algorithmen ausgestattet ist. In einer kritischen Situation, in der ein Fußgänger plötzlich auf die Straße läuft, muss das Fahrzeug entscheiden, ob es den Fußgänger ausweichen oder frontal mit einem anderen Fahrzeug kollidieren soll, was die Insassen gefährden könnte. Das Fahrzeug ist so programmiert, dass es priorisiert, die Verletzung von Menschenleben zu minimieren, aber die Algorithmen müssen Entscheidungen in Millisekunden treffen. In der Simulation gibt es mehrere Szenarien, in denen das Fahrzeug unterschiedliche Entscheidungen trifft, je nach den programmierten ethischen Richtlinien.
Eine Gesundheitsorganisation hat einen KI-Algorithmus entwickelt, der auf Basis von Patientendaten Diagnosen stellt und Behandlungsempfehlungen gibt. Der Algorithmus wird mit einer Vielzahl von Daten trainiert, einschließlich genetischer Informationen, medizinischer Vorgeschichte und Lebensstilfaktoren. In einer klinischen Testphase stellt sich heraus, dass der Algorithmus bei älteren Patienten und solchen mit seltenen Krankheiten häufig fehldiagnostiziert. Dies führt zu verzögerten oder falschen Behandlungen, was die Gesundheit der Patienten gefährdet. Zudem gibt es Bedenken hinsichtlich des Datenschutzes, da sensible Patientendaten in die KI eingespeist werden.
Eine Bank hat einen KI-gestützten Finanzberater entwickelt, der Kunden individuelle Investitionsstrategien vorschlägt. Der Algorithmus analysiert das finanzielle Verhalten der Nutzer, Markttrends und historische Daten, um maßgeschneiderte Empfehlungen zu geben. Während der Testphase zeigt sich jedoch, dass der Algorithmus tendiert, risikobehaftete Anlagen für jüngere Kunden und konservativere Anlagen für ältere Kunden zu empfehlen, ohne deren individuelle Risikobereitschaft ausreichend zu berücksichtigen.
Eine Polizeibehörde hat ein KI-System eingeführt, das predictive policing (vorausschauende Polizeiarbeit) betreibt. Das System analysiert historische Kriminalitätsdaten, um vorherzusagen, wo und wann Verbrechen wahrscheinlich auftreten werden. Während der Implementierung wird jedoch festgestellt, dass das System überproportional häufig in bestimmten Vierteln mit höherem Anteil an ethnischen Minderheiten aktiv wird, was zu vermehrten Kontrollen und Spannungen in der Anwohnerschaft führt.
Ein Agrarunternehmen hat ein KI-System entwickelt, das Landwirten hilft, den Ernteertrag durch präzise Wettervorhersagen, Bodenanalysen und Pflanzengesundheitsüberwachung zu optimieren. Während der Testphase zeigen Landwirte, die auf das KI-System angewiesen sind, erhöhte Erträge, jedoch wird auch berichtet, dass einige Kleinbauern, die keinen Zugang zu dieser Technologie haben, ins Hintertreffen geraten.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
-
-
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Nach Veröffentlichung der ethischen Leitlinien für den KI-Einsatz und die Entwicklung haben diverse Akteure Ansätze und Initiativen entwickelt um vertrauenswürdige (trustworthy) Systeme zu entwickeln und zu fördern. Vertrauenswürdige KI bezieht sich dabei auf die Entwicklung und den Einsatz von Künstlicher Intelligenz, die zuverlässig, ethisch und sicher ist. Sie sollte so gestaltet werden, dass sie keine ungewollten negativen Auswirkungen auf Gesellschaft, Individuen oder bestimmte Gruppen hat, unter anderem im Hinblick auf Diskriminierung und Ungleichbehandlung. Um diese Vertrauenswürdigkeit zu sichern, werden fortlaufend neue Instrumente, wie Frameworks, Normen, Gesetze und technische Werkzeuge implementiert.
Im Lauf der letzten Jahre haben sich Staaten, NGOs und Unternehmen durch KI-Richtlinien öffentlich zum Thema Ethik in der KI positioniert. Innerhalb der EU zieht sich der Prozess der Gesetzgebung und Normung zur europäischen KI-Verordnung seit 2021.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenFrameworks
Frameworks existieren, um eine strukturierte und systematische Bewertung von Technologien, wie beispielsweise Künstlicher Intelligenz, zu ermöglichen, um deren Qualität, Sicherheit und ethische Verantwortung sicherzustellen und so Vertrauen in ihre Anwendung und Entwicklung zu fördern.
Ein Beispiel für einen KI-Framework ist der vom Fraunhofer IAIS entwickelte KI-Prüfkatalog. Dieser dient dazu, die Vertrauenswürdigkeit von KI-Anwendungen systematisch zu bewerten. Er umfasst einen vierstufigen Prozess: Risikoanalyse, Festlegung messbarer Zielvorgaben, Maßnahmen entlang des Lebenszyklus und eine Argumentation zur Erreichung der festgelegten Ziele. Der Katalog deckt sechs Dimensionen der Vertrauenswürdigkeit ab, darunter auch Fairness, Transparenz und Sicherheit. Ziel ist es, Entwickler*innen und Prüfer*innen bei der Dokumentation und Evaluierung von KI-Anwendungen hinsichtlich ihrer Qualität und ethischen Anforderungen zu unterstützen.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Übersicht: Internationale Frameworks
KI-Prüfkatalog HUDERAF Framework OECD Framework VDE VCIO-Ansatz Model AI Governance Framework Institution, Nationalität Fraunhofer IAIS; Deutschland The Alan Turing Institute; EU & England OECD VDE; Deutschland pdpc; Singapur Dimensionen der Vertrauens-würdigkeit - Autonomie & Kontrolle
- Fairness
- Datenschutz
- Security & Safety
- Verlässlichkeit
- Transparenz
- Menschenrechte
- Rechte
- Grundfreiheiten
- Freiheiten
- Demokratie
- Rechtsstaatlichkeit
- Mensch & Planet
- wirtschaftlicher Kontext
- Daten & Input
- KI-Modell
- Aufgabe & Ausgabe
- Transparenz
- Accountability
- Datenschutz
- Fairness
- Verlässlichkeit
- Erklärbarkeit
- Transparenz
- Fairness
- Menschen-zentriertheit
Ansatz für die Risikobewertung Strukturierte Textform, die die Erörterung von Aufgaben unterstützt Fragebogen-Workflow mit festen Antwortkategorien/Summierung Nicht vorgesehen Einstufung in Vertrauenslevel A-G Strukturiert nach Organisationsstrukturen In Anlehnung an: Schmitz, A., Mock, M., Görge, R. et al. A global scale comparison of risk aggregation in AI assessment frameworks. AI Ethics (2024). https://doi.org/10.1007/s43681-024-00479-6 (CC BY 4.0)
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Monitoring bezieht sich auf die laufende Überwachung von KI-Systemen während ihres Betriebs, um sicherzustellen, dass sie ethischen Standards entsprechen und keine unerwünschten Verzerrungen erzeugen. Ein konkretes Beispiel hierfür ist Gesichtserkennungssoftware, die oft auf Verzerrungen überprüft wird, um sicherzustellen, dass sie alle demografischen Gruppen gleich behandelt . So zeigte eine Untersuchung von IBM Watson, dass deren Gesichtserkennungssoftware systematische Fehler bei der Identifikation von nicht-weißen Personen aufwies. Durch kontinuierliches Monitoring werden solche Verzerrungen frühzeitig identifiziert und können durch Anpassungen an den Algorithmen oder durch die Integration diverser Trainingsdaten behoben werden. Tools wie Fairness Indicators helfen dabei, die Ergebnisse von KI-Systemen in Bezug auf verschiedene demografische Gruppen zu überwachen und auf Diskriminierung zu überprüfen.
Auditing ist der formelle Prozess der unabhängigen Prüfung von KI-Systemen , um sicherzustellen, dass sie keine Diskriminierung oder Fehler verursachen und regulatorische Anforderungen erfüllen. Ein Beispiel für Auditing findet sich im Bereich der Kreditvergabe, wo KI-gestützte Systeme häufig auf Verzerrungen hin überprüft werden. Im Jahr 2019 zeigte eine Untersuchung des U.S. Consumer Financial Protection Bureau (CFPB), dass einige KI-basierte Kreditvergabesysteme unbewusst bestimmte ethnische Gruppen benachteiligten. Audits helfen, diese Verzerrungen zu erkennen und die Algorithmen entsprechend anzupassen.
Die Zertifizierung von KI-Systemen stellt sicher, dass diese alle erforderlichen ethischen, sicherheitsrelevanten und regulatorischen Standards erfüllen. Ein Beispiel für eine solche Zertifizierung ist das AI Trust Framework von TÜV Rheinland, das KI-Systeme zertifiziert, die internationalen Normen für Sicherheit und Ethik entsprechen. Diese Zertifizierung gibt den Nutzer*innen Vertrauen, dass die Technologie auf faire und transparente Weise funktioniert.
Podcasts-Tipp:
Wie vertrauenswürdig ist KI? Auf dem Weg zu einer KI-Zertifizierung »made in Germany«
https://www.fraunhofer.de/de/mediathek/podcasts/2024/podcast-vertrauenswuerdige-ki.html
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
EU KI-Verordnung
Als Reaktion auf die Bedenken in Bezug auf die ethische Nutzung und die Risken von KI, hat die Europäische Union (EU) mit dem Artificial Intelligence Act (AI Act), welcher einen neuen globalen Standard für die KI-Regulierung darstellen soll, am 1. August 2024 verabschiedet. Das wesentliche Ziel des Gesetzes ist die Erhaltung und der Schutz der Grundrechte, der Demokratie, der Rechtsstaatlichkeit sowie der ökologischen Nachhaltigkeit. Das Gesetz wird bis 2026 vollständig anwendbar sein, wobei Verbote nach sechs Monaten in Kraft treten, Governance-Regeln und Pflichten für allgemeine KI-Modelle nach zwölf Monaten gelten und die Vorschriften für KI-Systeme, die in regulierte Produkte eingebettet sind, nach 36 Monaten wirksam werden. Dabei zielt die Verordnung der EU darauf ab, ein Gleichgewicht zu schaffen zwischen der Innovationsförderung und der Wahrung der Rechte des Einzelnen. Die KI-Verordnung ordnet KI-Anwendungen in vier Risikostufen ein, für die jeweils andere Absicherungs- und/oder Transparenzanforderungen gestellt werden.
KI-Risikopyramide von Fraunhofer IAIS (CC BY-SA) -
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Praxisübung (Modul 3): Multiple Choice Quizz 💬
-
-
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Grundlagen Prompting
Prompts sind kurze Anweisungen oder Fragen, mit denen KI-Systeme – insbesondere Fundamentalmodelle – gesteuert werden, zum Beispiel zur Textgenerierung. Prompting bezeichnet die Technik, diese Anweisungen gezielt einzusetzen.
Bedeutung im Kontext generativer KI
In der Arbeit mit generativen Chatbots oder ähnlichen Systemen beeinflusst die Art und Weise, wie ein Prompt formuliert wird, maßgeblich den Output. Ein klarer, strukturierter und gut überlegter Prompt kann dazu beitragen, Missverständnisse zu vermeiden und das Risiko von Verzerrungen oder ungewollten Ergebnissen zu reduzieren. Ziel ist es, durch den richtigen Einsatz von Sprache und Detailgrad ein möglichst faires und zielgerichtetes Ergebnis zu erhalten. -
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Halluzinationen im Kontext von KI beziehen sich auf Inhalte, die von einem KI-Modell erzeugt werden und zwar realistisch wirken, jedoch von den ursprünglichen Eingaben abweichen. Dies wird als fehlende Übereinstimmung (faithfulness) oder mangelnde faktische Genauigkeit (factualness) bezeichnet.
Halluzinationen in KI-Modellen von Fraunhofer IAIS (CC BY-SA) -
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
C.R.E.A.T.E - Verbesserungsstrategie:
Zur Verbesserung des Outputs einer Anweisung an ein KI- System und zur Vermeidung von Halluzinationen gibt es bestimmte Strategien und Techniken die angewendet werden können. Hierzu zählt auch die sogenannte CREATE - Methode. Diese legt durch verschiedene Bestandteile sicher, das ein verbessertes Ergebnis erreicht werden kann. Insbesondere wird hierbei auf die Wichtigkeit von einer klaren und präzisen Formulierung, der Berücksichtigung des Kontextes und dem Einbringen von Feedback verwiesen. Die Create Methode setzt sich aus den Bestandteilen : Charakter, Request, Examples, Adjustment, Type of Output und Extras zusammen. Dabei sind bei den Bestandteilen folgenden Anmerkungen zu beachten:
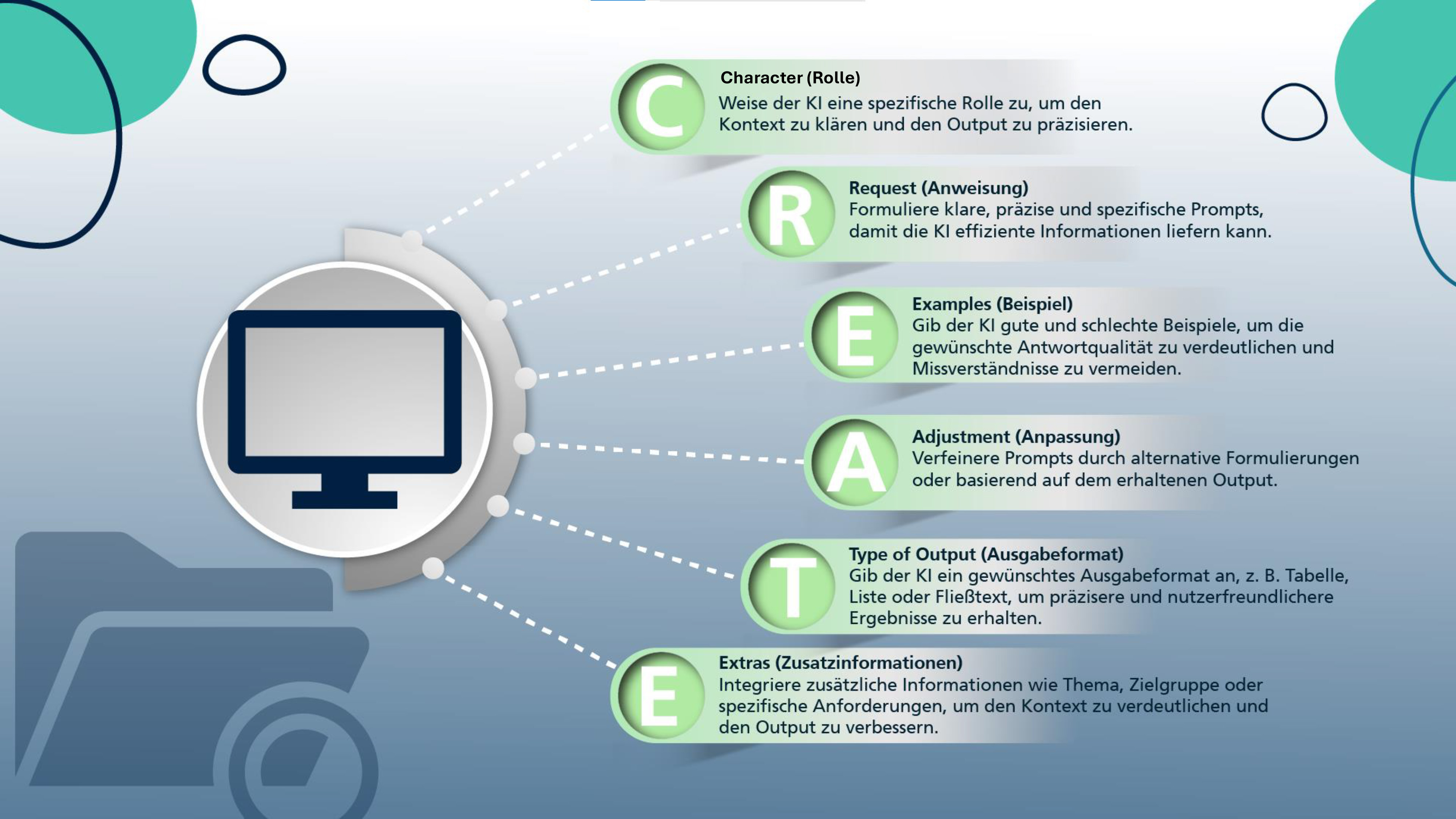
C.R.E.A.T.E. Framework von Fraunhofer IAIS (CC BY-SA) -
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenVerantwortungsvolles Prompting
Verantwortungsvolles Prompting erfordert neben der vorgestellten CREATE-Methode auch das Bewusstsein, dass Vorurteile und Bias in den Daten und Algorithmen existieren können, die den Output verzerren. Um diese Verzerrungen zu minimieren und ein inklusives Prompting zu fördern, sollten zusätzlich zur CREATE-Methode weitere Aspekte in die Promptformulierung und -bewertung einfließen. Diese Ansätze können sowohl auf das Generieren von Texten, als auch Bildern angewendet werden. Ein zentrales Konzept hinter diesen Methoden ist es, toxische Positivität und stereotype Ausgaben zu vermeiden. Toxische Positivität bezeichnet dabei die Tendenz, realistische Darstellungen in Bild- und Textformat zu unterdrücken und stattdessen durch sozial akzeptable, aber möglicherweise verzerrte Darstellungen zu ersetzen.
Hier einige konkrete Tipps:
- Integriere Perspektivenwechsel:
Verwende Prompts, die das Modell anweisen, sich in verschiedene Nutzergruppen hineinzuversetzen. Beispielsweise:- „Stelle dir vor, du liest diesen Text als jemand aus einer unterrepräsentierten Gruppe. Welche Wirkung könnte er haben?“
Dies hilft, mögliche Diskriminierungen frühzeitig zu erkennen und zu vermeiden.
- „Stelle dir vor, du liest diesen Text als jemand aus einer unterrepräsentierten Gruppe. Welche Wirkung könnte er haben?“
- Teste und variiere systematisch:
Nutze einen iterativen Ansatz, um verschiedene Prompt-Varianten zu generieren und zu vergleichen. So können ungewollte Effekte identifiziert und gezielt minimiert werden. - Implementiere Feedbackschleifen:
Integriere Selbstkorrekturmechanismen, bei denen das Modell seine eigenen Antworten überprüft. Zum Beispiel:- „Überprüfe, ob deine Antwort Vorurteile enthält, und passe sie gegebenenfalls an.“
Dies fördert die Selbstregulation und reduziert das Risiko von toxischen oder verzerrten Inhalten.
- „Überprüfe, ob deine Antwort Vorurteile enthält, und passe sie gegebenenfalls an.“
Diese Tipps helfen, Prompts so zu gestalten, dass sie fair, diversitätssensibel und robust gegenüber unerwünschten Effekten sind – und stützen sich auf Erkenntnisse aus aktuellen Forschungsansätzen im Bereich der KI-Sicherheit und Bias-Reduktion.
Anmerkung:
Ein standardisiertes Framework für verantwortungsbewusstes bzw. inklusives Prompting existiert derzeit noch nicht.
Weiterführende Literatur:
- Integriere Perspektivenwechsel:
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Achtung ❗
Es handelt sich um ein generatives Sprachmodell von OpenAI. Bitte beachte den Datenschutz und gib keine persönlichen Informationen ein. Achte außerdem darauf, dass Sprachmodelle halluzinieren können und der Output gegebenenfalls sinnfrei, irreführend oder diskriminierend sein kann.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Aufgabe (Modul 4): Erstelle einen effektiven und zugleich verantwortungsvollen Prompt
- Rolle des KI-Modells: Entscheide, welche Rolle du dem KI-Modell zuweisen möchtest (z.B. Lehrer*in, Berater*in, Historiker*in, Wissenschaftler*in, Marketing-Expert*in).
- Beispiel: "Du bist ein Marketing-Expert*in, der eine Zielgruppenanalyse für ein neues Produkt durchführt."
- Anforderung: Formuliere eine präzise und klare Anfrage, die auf die gewünschte Antwort hinführt. Achte darauf, dass keine vagen Formulierungen verwendet werden.
- Beispiel: "Analysiere die Zielgruppe für ein neues umweltfreundliches Produkt und nenne die wichtigsten demografischen Merkmale, die für das Marketing wichtig sind."
- Beispiel für gute Antworten: Gib dem KI-Modell Beispiele für die Art von Antworten, die du dir wünschst.
- Beispiel: "Die Zielgruppe umfasst vor allem umweltbewusste Konsumenten im Alter von 25-40 Jahren, die ein mittleres bis hohes Einkommen haben und in städtischen Gebieten leben."
- Beispiel für schlechte Antworten: Gib auch ein Beispiel, was du vermeiden möchtest.
- Beispiel: "Jeder kann das Produkt kaufen, es gibt keine Zielgruppe."
- Verfeinerung: Basierend auf der ersten Antwort kannst du Anpassungen an deinem Prompt vornehmen, um eine noch präzisere Antwort zu erhalten.
- Beispiel: "Kannst du mehr Details zu den psychografischen Merkmalen der Zielgruppe hinzufügen?"
- Ausgabeformat: Gib an, in welchem Format die Antwort erfolgen soll (z.B. Liste, Fließtext, Tabelle).
- Beispiel: "Bitte präsentiere die Zielgruppenanalyse als Bulletpoints."
- Zusatzinformationen: Überlege, ob es noch weitere Kontextinformationen gibt, die das KI-Modell zur besseren Beantwortung braucht.
- Beispiel: "Berücksichtige, dass das Produkt vor allem in europäischen Märkten verkauft werden soll."
- Vorurteile und Bias: Überarbeite deinen Prompt auf mögliche Verzerrungen und Formulierungen, die bestimmte Gruppen ausschließen oder ungewollte Stereotype fördern könnten.
- Beispiel: „Hast du in der Zielgruppenanalyse darauf geachtet, keine stereotype Annahmen über bestimmte Altersgruppen oder sozioökonomische Status zu treffen?“
- Perspektivenwechsel: Formuliere den Prompt so, dass er auch aus der Perspektive einer unterrepräsentierten Gruppe sinnvoll ist.
- Beispiel: "Stelle dir vor, du liest diese Zielgruppenanalyse als Mitglied einer kleinen, umweltbewussten Gruppe. Welche Teile der Analyse wären besonders wichtig oder hilfreich für dich?"
- Selbstkorrektur: Gib dem KI-Modell die Aufgabe, seine Antwort auf mögliche Vorurteile oder Verzerrungen zu überprüfen.
- Beispiel: „Überprüfe bitte, ob deine Antwort eventuell Vorurteile gegenüber bestimmten Altersgruppen oder Einkommen enthält und passe sie gegebenenfalls an.“
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
-
-
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
-