Modul 1: KI und Biases 🤖
Abschnittsübersicht
-
Künstliche Intelligenz (KI) ist allgegenwärtig – von Sprachassistenten über Bilderkennung bis hin zu Empfehlungssystemen auf sozialen Plattformen prägt sie unseren Alltag. Doch was verbirgt sich hinter Begriffen wie Künstliche Intelligenz (KI), Maschinelles Lernen (ML), Deep Learning und Natural Language Processing (NLP)? Bevor wir tiefer in die Materie eintauchen, klären wir zunächst diese grundlegenden Konzepte.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
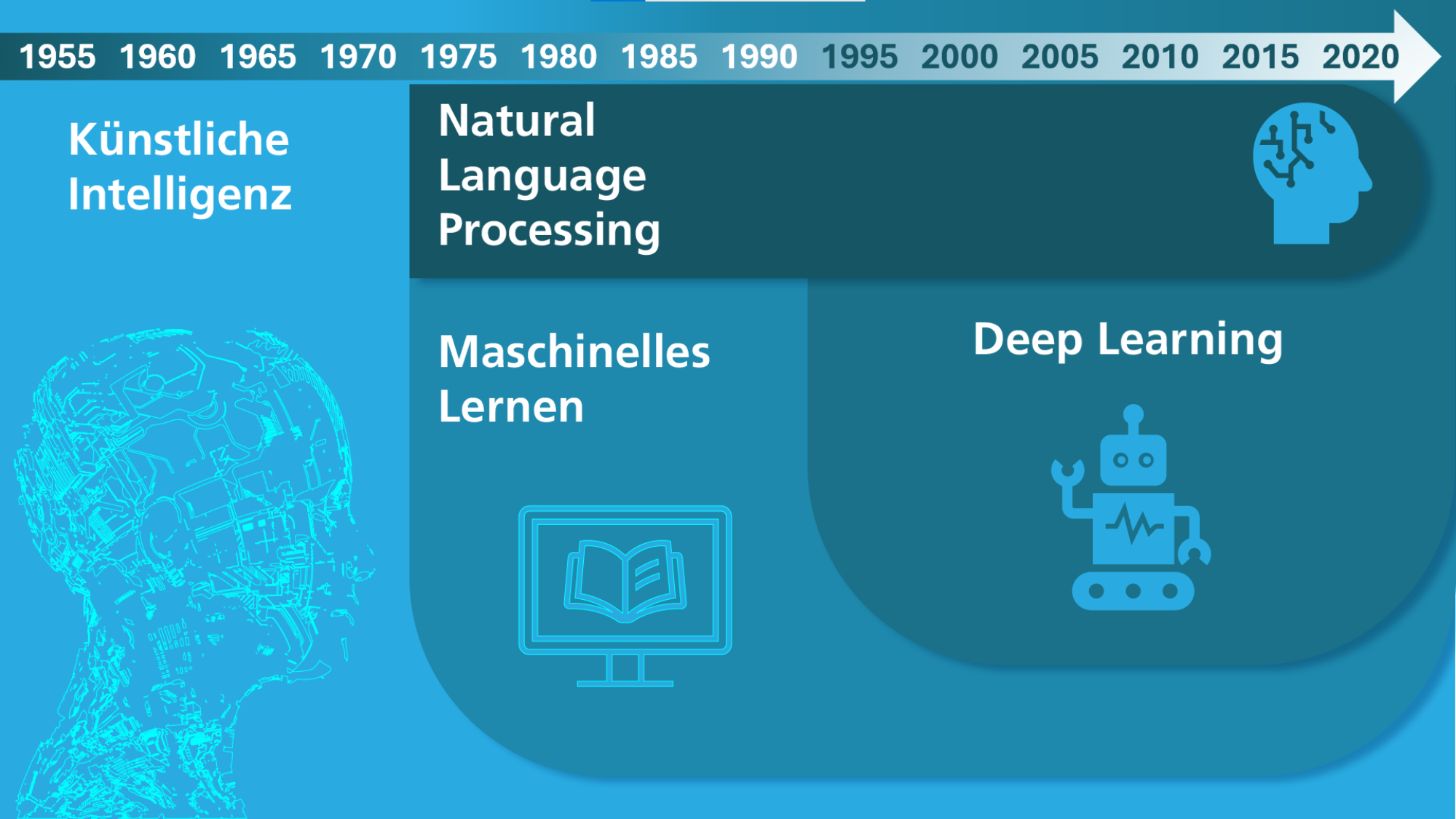
KI-Historie von Fraunhofer IAIS (CC BY-SA 4.0) -
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Künstliche Intelligenz (KI) ist ein Teilgebiet der Informatik, und befasst sich damit, wie ein Computer intelligentes, menschliches Verhalten nachahmen kann. Dabei ist weder festgelegt, was »intelligent« bedeutet, noch welche Technik zum Einsatz kommt. Eine der Grundlagen der modernen KI ist das Maschinelle Lernen.
Machine Learning (Maschinelles Lernen): Durch selbst lernende Algorithmen analysieren Computerprogramme Datensätze und erkennen Muster und Gesetzmäßigkeiten, ohne dafür explizit programmiert zu sein. Es wird als ein Teilgebiet der KI definiert, wobei diverse Ansätze, einschließlich tiefen neuronalen Netzen, eingesetzt werden. Im Gegensatz zur (subsymbolischen) KI, die auf die Nachahmung von Gehirnfunktionen ausgerichtet ist, beruht maschinelles Lernen darauf, Modelle automatisch zu optimieren, indem Trainingsdaten analysiert und daraus Erkenntnisse gewonnen werden. Maschinelles Lernen (ML) kommt unter anderem in Spam-Filtern zum Einsatz, wo Algorithmen wie Naive Bayes unerwünschte E-Mails automatisch erkennen. Auch in der dynamischen Preisgestaltung wird ML genutzt, um Preise in Echtzeit basierend auf Angebot und Nachfrage anzupassen. In der Sportanalyse helfen Methoden wie Regression oder k-nearest neighbors dabei, die Leistung von Spielern vorherzusagen oder taktische Entscheidungen zu unterstützen.
Deep Learning beschreibt die Umsetzung eines maschinellen Lernverfahrens in Form eines künstlichen neuronalen Netzes. Die Erzeugung der relevanten Merkmale für das Lernen erfolgt selbsttätig. Künstliche neuronale Netze, inspiriert von neuronalen Netzwerken des menschlichen Gehirns, sind zentrale Komponenten des Deep Learning. Sie bestehen aus mehreren Neuronen, auch Units genannt, die Informationen aus der Umwelt oder von anderen Neuronen aufnehmen und diese in modifizierter Form an andere Units oder die Umwelt weiterleiten. Die Units sind durch Kanten miteinander verbunden, wobei die Stärke der Verbindung zwischen zwei Neuronen durch ein Gewicht ausgedrückt wird. Wissen wird in diesen Gewichten gespeichert, und Lernen erfolgt durch schrittweise Gewichtsveränderungen.
Die Struktur der neuronalen Netze umfasst verschiedene Typen von Units:
- Input Units: Diese nehmen die notwendigen Informationen auf, verarbeiten die verwendeten Daten und geben sie mit einem Gewicht an die nächste Schicht weiter.
- Hidden Units: Diese Schicht(en) befindet sich zwischen den Input und Output Units. Hier können beliebig viele Neuron-Ebenen verwendet werden. Die empfangenen Informationen werden erneut gewichtet und von Neuron zu Neuron an die Output Units weitergereicht. Die genaue Prozessierung der Informationen in den Hidden Units bleibt dabei undurchsichtig und wird oft als Black Box bezeichnet.
- Output Units: Diese bilden die letzte Ebene des Netzes und schließen unmittelbar an die Hidden Units an. Die Output-Neuronen enthalten die resultierenden Entscheidungen.
Insgesamt ermöglichen künstliche neuronale Netze eine komplexe Verarbeitung von Informationen durch die dynamische Anpassung der Gewichtungen zwischen den Neuronen, wodurch sie in der Lage sind, aus Daten zu lernen und Entscheidungen zu treffen.
Praxisbeispiele für Deep Learning und neuronale Netze
1. Bilderkennung in der Medizin
- Deep-Learning-Modelle werden genutzt, um Röntgen- oder MRT-Bilder zu analysieren und Anomalien wie Tumore zu identifizieren.
- Beispiel: Ein neuronales Netz wird mit tausenden Bildern trainiert, um Krebszellen von gesunden Zellen zu unterscheiden
2. Autonomes Fahren
- Sensoren in autonom fahrenden Autos liefern Daten an ein neuronales Netz, das Objekte erkennt (z. B. Fußgänger, Verkehrsschilder) und darauf reagiert.
- Die Deep-Learning-Modelle lernen aus Millionen von Straßenaufnahmen, wie Personen Entscheidungen treffen.
3. Betrugserkennung im Finanzwesen
- Banken nutzen Deep Learning, um betrügerische Transaktionen zu erkennen.
- Ein neuronales Netz analysiert Zahlungshistorien und warnt bei ungewöhnlichen Transaktionen
Natürliche Sprachverarbeitung (Natural Language Processing, NLP) ist ein Teilgebiet der KI und beschäftigt sich mit der Interaktion zwischen Computern und menschlicher Sprache. Das Ziel von NLP ist es, Maschinen zu ermöglichen, gesprochene und geschriebene Sprache zu verstehen, zu interpretieren und zu generieren. NLP kombiniert Methoden aus der Informatik, der Linguistik und dem maschinellen Lernen, um komplexe sprachbezogene Aufgaben zu bewältigen.
NLP profitiert auch von Fortschritten im Bereich des Deep Learning, insbesondere durch den Einsatz neuronaler Netze, die Sprach- und Fundamentalmodelle auf Basis großer Datenmengen trainieren. Dabei kommen mehrschichtige neuronale Netze (Deep Learning) zum Einsatz, die es ermöglichen, semantische und syntaktische Strukturen in Texten zu erfassen.
Wichtige Anwendungsbereiche von NLP
- Intelligente Übersetzung: Systeme wie DeepL nutzen NLP-Algorithmen, um Texte automatisch von einer Sprache in eine andere zu übersetzen.
- Sprachassistenzsysteme: Virtuelle Assistenten wie Siri, Alexa oder Google Assistant basieren auf NLP-Ansätzen, um Benutzereingaben zu verstehen und passende Antworten zu generieren.
- Textanalyse und Sentimentanalyse: Unternehmen nutzen NLP zur automatischen Analyse von Kundenbewertungen oder Social-Media-Beiträgen, um Meinungen und Stimmungen zu extrahieren.
- Automatische Textgenerierung: Anwendungen wie Chatbots oder Nachrichtengeneratoren nutzen NLP-Methoden, um kohärente und relevante Texte zu verfassen.
- Informationsgewinnung: NLP ermöglicht es, aus großen Textmengen automatisch relevante Informationen zu extrahieren, z. B. in der medizinischen Diagnostik oder im juristischen Bereich.
Technologische Grundlagen von NLP
- Tokenization: Aufspaltung eines Textes in kleinere Einheiten (Wörter oder Sätze).
- Part-of-Speech-Tagging: Bestimmung der Wortart eines Begriffs im Kontext eines Satzes.
- Named Entity Recognition (NER): Identifikation von Eigennamen, Orten oder Organisationen in einem Text.
- Syntax- und Semantikanalyse: Untersuchung der grammatikalischen Struktur und der inhaltlichen Bedeutung eines Satzes.
- Word Embeddings: Repräsentation von Wörtern als Vektoren in einem semantischen Raum, um Bedeutungsähnlichkeiten abzubilden (z. B. Word2Vec, GloVe, BERT).
Zukunftsperspektiven von NLP
Die Weiterentwicklung von NLP wird durch immer leistungsfähigere neuronale Netzwerke und große Sprachmodelle wie GPT oder BERT, sogenannten Transformer-Architekturen, vorangetrieben. In Zukunft könnte NLP noch präzisere und menschenähnliche Interaktionen ermöglichen, wodurch es in immer mehr Anwendungsfeldern eine zentrale Rolle spielen wird. Herausforderungen wie die Erkennung von Ironie, die Berücksichtigung von Kontext oder die Reduzierung von Vorurteilen in Trainingsdaten bleiben jedoch bestehen und sind Gegenstand aktueller Forschung.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
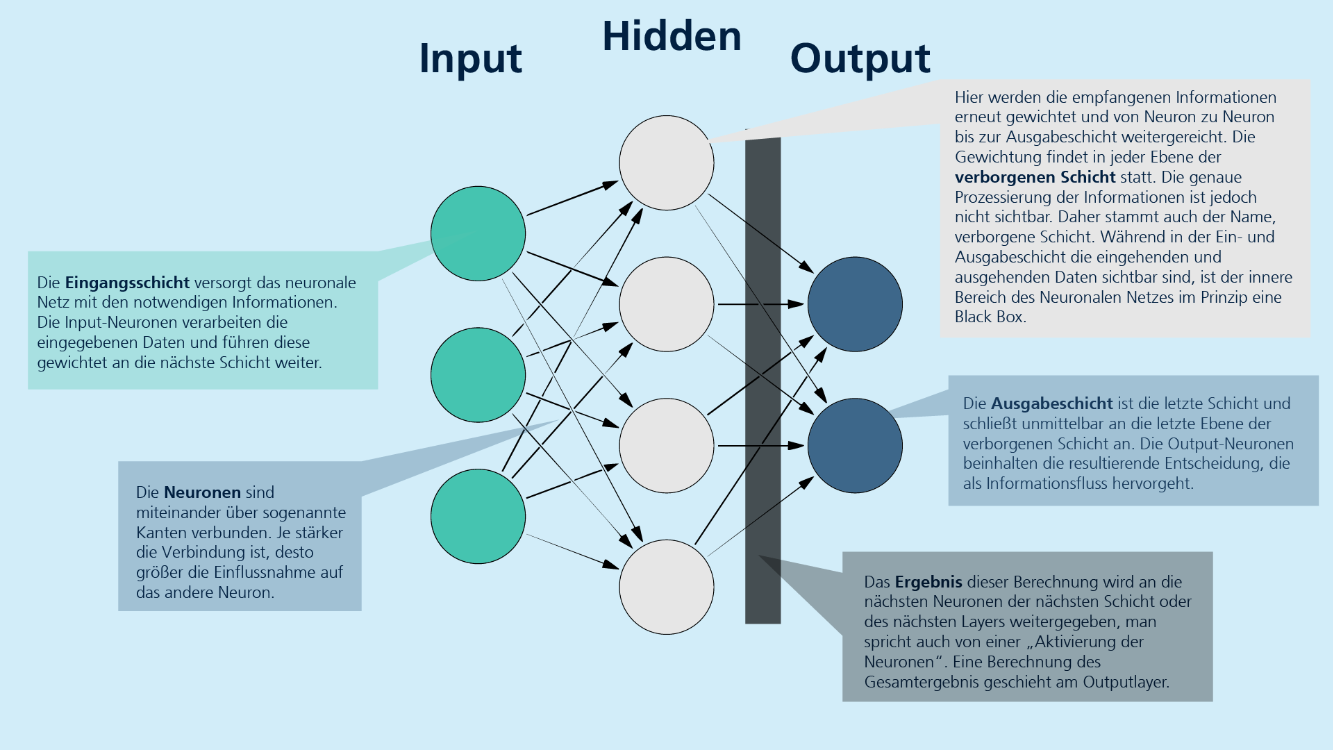
Aufbau von künstlichen Neuronalen Netzen von Fraunhofer IAIS (CC BY-SA) -
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenTool-Liste: 🔨
Neuronale Netze einsteigerfreundlich selbst programmieren:
Neuronale Netze ohne Coding trainieren:
NLP und Sprachmodelle verstehen:
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
KI-Systeme sind nicht neutral: Verzerrungen in Daten und Algorithmen können zu unfairen oder diskriminierenden Entscheidungen führen – doch welche Arten von Bias gibt es, und wie entstehen sie?
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenArten von Biases
Die Dimensionen von Diversität, wie ethnischer Hintergrund, Geschlecht, Alter, sexuelle Orientierung, Religion, soziale Herkunft sowie körperliche und geistige Fähigkeiten, prägen die Vielfalt innerhalb einer Gesellschaft. Diese Aspekte beeinflussen maßgeblich, wie Menschen leben und miteinander interagieren. Das Ziel von Diversitätsförderung ist es, eine Gesellschaft zu schaffen, in der alle Menschen gleiche Chancen und Rechte genießen. Chancengleichheit, die Innovationskraft durch verschiedene Perspektiven sowie die Förderung von Inklusion sind hierbei zentrale Elemente. Ein respektvoller interkultureller Dialog spielt ebenso eine wichtige Rolle, um gesellschaftliche Kohäsion zu fördern und eine offene sowie gerechte Gemeinschaft zu schaffen.
In einer zunehmend digitalisierten Welt beeinflussen diese Dimensionen der Diversität jedoch auch die Technologieentwicklung, insbesondere im Bereich der KI. Ein Bias, oder eine systematische Verzerrung in der Wahrnehmung, im Denken oder in der Entscheidungsfindung, kann in KI-Algorithmen (unbewusst) eingebaut sein. Solche Verzerrungen führen dazu, dass Informationen selektiv interpretiert oder bewertet werden, was zu inkorrekten und potenziell diskriminierenden Bewertungen führen kann. Im Rahmen des maschinellen Lernens ist es wichtig, zwischen direkter Bias-Wirkung (Disparate-Impact) und indirekte Beziehungen (Disparate Treatment) zu unterscheiden, da der Einsatz von KI- Algorithmen nicht automatisch Bias-Effekte vermeidet. Die Algorithmen müssen genau auf die jeweilige Situation abgestimmt werden. Selbst wenn sensible Attribute wie Alter, Religionszugehörigkeit oder Geschlecht aus den Daten entfernt werden, können Algorithmen, die auf diesen Daten trainiert werden, dennoch ungewollte diskriminierende Inhalte produzieren.
Bias-Arten wie bspw. Selektionsbias (durch unausgewogene Trainingsdaten), Bestätigungsbias (Verstärkung von Vorurteilen durch Algorithmen) und historischer Bias (veraltete Daten, die Diskriminierung abbilden) werden in der Literatur unterschiedlich definiert.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenUrsachen & Auswirkungen von Biases in Datensätzen und im Training von Modellen
Diskriminierung in KI-Systemen kann durch verschiedene Ursachen bedingt sein.
Häufige Ursachen für Biases
- In den Trainingsdaten:
- Historische Ungleichheiten werden reflektiert und verstärkt.
- Fehlende oder unausgewogene Daten sorgen für eine verzerrte Repräsentation.
- Sensible Merkmale können auch indirekt über Proxy-Attribute Einfluss nehmen.
- Im Modell selbst:
- Programmierte Entscheidungsregeln können unbeabsichtigt diskriminierende Auswirkungen haben.
- Entwickler*innen übertragen unbewusst Stereotype oder gesellschaftliche Vorurteile auf das Modell. Neuronale Netze und andere komplexe Modellarchitekturen agieren oft als "Black Boxes", bei denen es schwierig ist, die genauen Entscheidungswege nachzuvollziehen. Gewichtsanpassungen und versteckte Schichten können dazu führen, dass Verzerrungen unbewusst in den Entscheidungsprozess eingeführt werden, ohne dass Entwickler*innen dies erkennen.
- Während der Modellanwendung und -optimierung:
- KI-Modelle, die sich kontinuierlich weiterentwickeln, können unbeabsichtigt Diskriminierung verstärken.
- Fehlende Audits oder menschliche Kontrollinstanzen können dazu führen, dass diskriminierende Entscheidungen nicht erkannt oder korrigiert werden.
Diskriminierung in KI-Systemen kann auf verschiedene Weise zum Vorschein kommen, insbesondere in Bereichen wie Gesichtserkennung, Arbeitsmarkt, Kreditvergabe und Gesundheitswesen. Bei der Gesichtserkennung zeigen sich Probleme wie eine schlechte Erkennung von dunkelhäutigen oder weiblichen Menschen, was zu diskriminierenden Ergebnissen in Anwendungen wie dem Entsperren von Smartphones oder der Strafverfolgung führt. Im Arbeitsmarkt können KI-gestützte Systeme zur Vorsortierung von Bewerbungen Diskriminierung aufgrund von Alter, Geschlecht oder ethnischer Herkunft fördern. Ähnliche Probleme bestehen bei der automatischen Einschätzung der Kreditwürdigkeit, wo ebenfalls Alters- und Geschlechtsdiskriminierung auftreten kann. Im Gesundheitsbereich sind Gesundheits-Apps gelegentlich nicht ausreichend auf die Bedürfnisse unterrepräsentierter Gruppen zugeschnitten, was zu einer Geschlechterlücke in den Daten und unzureichender Berücksichtigung spezifischer medizinischer Probleme führen kann.
Um KI gerechter zu gestalten, braucht es gezielte Maßnahmen: Diversität in Datensätzen, Fairness-Algorithmen und transparente Entwicklungsprozesse können helfen, Verzerrungen zu reduzieren.
- In den Trainingsdaten:
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen

Gesichtserkennung mithilfe künstlicher Neuronaler Netze von Fraunhofer IAIS (CC BY-SA) -
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenDiversitätssensible Ansätze
Um Bias in KI-Systemen zu minimieren, sind mehrere strategische Ansätze erforderlich, die sowohl technische als auch gesellschaftliche Aspekte berücksichtigen. Ein zentraler Schritt besteht darin, die Diversität in den Datensätzen sicherzustellen. Dies bedeutet, dass alle relevanten Gruppen in den Daten repräsentiert sein müssen, um Verzerrungen zu verhindern und eine faire Grundlage für die Modellbildung zu schaffen. Eine gezielte und breit angelegte Datenerhebung hilft dabei, systematische Ungleichheiten zu vermeiden und sicherzustellen, dass KI-Modelle nicht ungewollt bestehende Diskriminierungen verstärken. Darüber hinaus sollten Fairness-Algorithmen in den Entwicklungsprozess integriert werden. Diese mathematischen Verfahren erkennen und korrigieren Verzerrungen, die in den Modellen entstehen können, und tragen dazu bei, dass die Entscheidungen eines KI-Systems für alle betroffenen Gruppen gleichermaßen gerecht sind. Regelmäßige Audits und eine hohe Transparenz der KI-Systeme sind ebenfalls entscheidend. Ein weiterer wichtiger Aspekt ist die interdisziplinäre Zusammenarbeit bei der Entwicklung von KI-Systemen. Expert*innen bspw. aus den Bereichen Ethik, Recht und Sozialwissenschaften sollten von Anfang an in den Entwicklungsprozess eingebunden werden. Dies gewährleistet, dass die KI-Systeme nicht nur aus einer technischen Perspektive, sondern auch aus sozialen und ethischen Gesichtspunkten betrachtet werden, um unbewusste Vorurteile zu minimieren und den sozialen Verantwortung gerecht zu werden.
Diese ganzheitliche Herangehensweise trägt dazu bei, dass KI-Technologien langfristig fair und verantwortungsbewusst eingesetzt werden. Es ist jedoch wichtig zu betonen, dass KI niemals vollständig frei von Bias sein kann. Da KI-Systeme auf historischen Daten basieren, die menschliche Entscheidungen und gesellschaftliche Strukturen widerspiegeln, sind sie immer in gewissem Maße von bestehenden Vorurteilen und Ungleichgewichten beeinflusst. Auch wenn durch bspw. sorgfältige Auswahl der Daten und den Einsatz von Fairness-Algorithmen Verzerrungen minimiert werden können, bleibt die Möglichkeit von unbeabsichtigten Biases bestehen. KI kann also niemals völlig „neutral“ oder „unvoreingenommen“ sein, doch durch kontinuierliche Überwachung und Anpassung können wir ihre Auswirkungen erheblich reduzieren und den verantwortungsvollen Einsatz sicherstellen. Eine Vertiefung mit Blick auf eine vertrauenswürdige Entwicklung von KI-Modellen findet sich in den Modulen zwei und drei.
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnenMethoden und Strategien zur Erkennung und Minimierung von Biases für Nutzer*innen
Für KI-Nutzer*innen, die keinen direkten Einblick in Trainingsdaten oder den Entwicklungsprozess haben, stehen primär indirekte Ansätze zur Verfügung, um potenzielle Biases zu erkennen und deren Auswirkungen zu minimieren. Nutzer*innen können sich beispielsweise auf transparente Informationen und unabhängige Prüfberichte der Anbieter stützen – etwa Zertifizierungen, Fairness-Audits oder Evaluierungsberichte, die Aufschluss darüber geben, inwiefern das System auf Verzerrungen getestet wurde. Ebenso können bspw. öffentliche Berichterstattungen oder Diskussionen und Beiträge auf sozialen Plattformen Erkenntnisse über die die Verlässlichkeit und Transparenz der Systeme eines Anbieters liefern. Zudem hilft es, durch eigene Beobachtungen und systematische Tests, wie das Ausprobieren verschiedener Eingaben, Unregelmäßigkeiten in den Ergebnissen zu erkennen (s. Modul 4).
-
AbschlussTeilnehmer/innen müssenAls erledigt kennzeichnen
Praxisübung (Modul 1): Multiple Choice Quizz 💬
-