1.2 Types of AI: Weak vs. strong AI
1.2 Types of AI: Weak vs. strong AI
AI often seems magical, but behind the scenes it relies on probabilities and vast amounts of data. So how far can AI think?
Key question: What is possible?
The most fundamental distinction between AI systems concerns the scope of their capabilities:
- Weak (or narrow) AI is limited to clearly defined tasks. It follows fixed rules and reacts to defined inputs – for example, in the transcription of lectures, plagiarism detection, spatial planning or the modelling of complex systems. Such systems only function within their specialist field – they are neither creative nor flexible. All AI applications in use today fall into this category.
- Strong (or general) AI, on the other hand, could independently recognise tasks, acquire knowledge, analyse problems and develop creative solutions. Such systems do not yet exist, although advanced chatbots are coming closer to this ideal.
A distinction is often made between Artificial General Intelligence (AGI) – i.e. human-like intelligence – and a hypothetical Artificial Superintelligence (ASI), which far surpasses human capabilities. These concepts are theoretical, and ‘superintelligence’ in particular is problematic, because: even narrow AIs already outperform humans in certain specific tasks (e.g. computing power).
📌 Practical relevance: This distinction helps guard against unrealistic expectations. An AI designed for exam registration will never ‘think for itself’, but will merely replicate predefined patterns.
Learning paradigms: How AI learns
Machine learning (ML) can be divided into three fundamental paradigms:
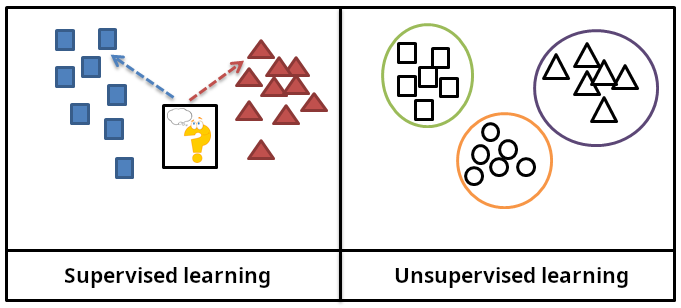
Supervised learning
Models are trained using labelled data – i.e. inputs to which an expected output value is assigned. The aim is to correctly predict new inputs. During the training process, the algorithm develops functions that are increasingly capable of determining the expected value for new, previously unseen data.
📌 Example: Predicting academic success based on historical performance data.
{kind=link}
Unsupervised learning
Here, models work with unlabelled data. Algorithms independently identify patterns, groups or structures (e.g. interests, subjects or numerical values). During the training process, algorithms learn relationships between these data: similarities and differences.
📌 Example: Clustering students by interests to recommend personalised learning content. This means: students are grouped based on their shared or differing interests. They can then be recommended learning content from the interest group to which they belong, which they have not previously specified themselves.
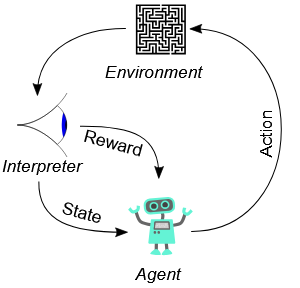
Reinforcement learning
A so-called agent interacts with an environment, tries out actions and learns through rewards or penalties. The aim is to develop strategies that yield the highest reward in the long term. Training and application cannot always be separated as clearly as in supervised and unsupervised learning, but arise from the agent’s interaction with the real world: Initially, random actions are tried out; this is referred to as exploration. Once the agent has learnt what works, it increasingly focuses on actions that promise greater reward; this is referred to as exploitation.
📌 Example: Learning path generator.
An agent selects topics/concepts for students’ learning paths and receives a reward or penalty depending on their success or failure.
{kind=link}
Hybrid forms and combinations
In addition to the classic paradigms, there are hybrid forms:
- Semi-supervised learning: Only part of the data is labelled. The model first learns from these, then automatically assigns labels to the rest.
- Self-supervised learning: The model generates training data (labels) itself using algorithms.
- Transfer learning: A pre-trained model, which is already good at recognising images, for example, is reused for a new, specialised task, such as categorising images even better.
Combinations are used in the training of many methods. For example, the training of chat assistants such as ChatGPT consists of several steps. In pre-training, a basic understanding of language is developed from very large amounts of text through self-supervised learning.
In the subsequent fine-tuning phase, models are presented with typical dialogue examples to learn how conversations work. And in a further step, reinforcement learning with live feedback from humans can be used to evaluate responses, which further improves conversational ability.
Here is an overview of the types of learning and their underlying patterns, along with examples from a university context:
| Learning method | Mechanism | University example |
| Supervised learning | Learning from labelled data | Predicting academic success |
| Unsupervised learning | Learning from unlabelled data | Clustering research data by topic |
| Reinforcement learning | Reward for successful action | Optimising energy management in campus buildings |
| Self-supervised learning | Independent labelling and learning of structures | Training generative language models such as ChatGPT with public texts |
💡 Learning Summary Chapter 1.2: Types of AI
- Weak vs. strong AI: Whilst weak AI solves specific tasks according to fixed rules, strong AI describes the theoretical ability to independently recognise problems and solve them creatively – an ideal that has not yet been achieved.
- Learning paradigms in AI: Machine learning takes place, for example, in a supervised (with labels), unsupervised (without labels) or reinforcement (with reward systems) manner. Modern AI often combines several of these paradigms.
Source reference
- Superintelligence, Nick Bostrom
- The Master Algorithm, Pedro Domingos